This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
Components
Prow Images
This directory includes a sub directory for every Prow component and is where all binary and container images are built. You can find the main packages here. For details about building the binaries and images see “Building, Testing, and Updating Prow”.
Cluster Components
Prow has a microservice architecture implemented as a collection of container images that run as Kubernetes deployments. A brief description of each service component is provided here.
Core Components
crier (doc, code) reports on ProwJob status changes. Can be configured to report to gerrit, github, pubsub, slack, etc.deck (doc, code) presents a nice view of recent jobs, command and plugin help information, the current status and history of merge automation, and a dashboard for PR authors.hook (doc, code) is the most important piece. It is a stateless server that listens for GitHub webhooks and dispatches them to the appropriate plugins. Hook’s plugins are used to trigger jobs, implement ‘slash’ commands, post to Slack, and more. See the plugins doc and code directory for more information on plugins.horologium (doc, code) triggers periodic jobs when necessary.prow-controller-manager (doc, code) manages the job execution and lifecycle for jobs that run in k8s pods. It currently acts as a replacement for planksinker (doc, code) cleans up old jobs and pods.
Merge Automation
tide (doc, code) manages retesting and merging PRs once they meet the configured merge criteria. See its README for more information.
Optional Components
branchprotector (doc, code) configures github branch protection according to a specified policyexporter (doc, code) exposes metrics about ProwJobs not directly related to a specific Prow componentgcsupload (doc, code)gerrit (doc, code) is a Prow-gerrit adapter for handling CI on gerrit workflowshmac (doc, code) updates HMAC tokens, GitHub webhooks and HMAC secrets for the orgs/repos specified in the Prow config filejenkins-operator (doc, code) is the controller that manages jobs that run on Jenkins. We moved away from using this component in favor of running all jobs on Kubernetes.tot (doc, code) vends sequential build numbers. Tot is only necessary for integration with automation that expects sequential build numbers. If Tot is not used, Prow automatically generates build numbers that are monotonically increasing, but not sequential.status-reconciler (doc, code) ensures changes to blocking presubmits in Prow configuration does not cause in-flight GitHub PRs to get stucksub (doc, code) listen to Cloud Pub/Sub notification to trigger Prow Jobs.
checkconfig (doc, code) loads and verifies the configuration, useful as a pre-submit.config-bootstrapper (doc, code) bootstraps a configuration that would be incrementally updated by the updateconfig Prow plugingeneric-autobumper (doc, code) automates image version upgrades (e.g. for a Prow deployment) by opening a PR with images changed to their latest version according to a config file.invitations-accepter (doc, code) approves all pending GitHub repository invitationsmkpj (doc, code) creates ProwJobs using Prow configuration.mkpod (doc, code) creates Pods from ProwJobs.peribolos (doc, code) manages GitHub org, team and membership settings according to a config file. Used by kubernetes/orgphaino (doc, code) runs an approximation of a ProwJob on your local workstationphony (doc, code) sends fake webhooks for testing hook and plugins.
Pod Utilities
These are small tools that are automatically added to ProwJob pods for jobs that request pod decoration. They are used to transparently provide source code cloning and upload of metadata, logs, and job artifacts to persistent storage. See their README for more information.
Base Images
The container images in images are used as base images for Prow components.
TODO: undocumented
Deprecated
1 - Core Components
1.1 - Crier
Crier reports your prowjobs on their status changes.
Usage / How to enable existing available reporters
For any reporter you want to use, you need to mount your prow configs and specify --config-path and job-config-path
flag as most of other prow controllers do.
You can enable gerrit reporter in crier by specifying --gerrit-workers=n flag.
Similar to the gerrit adapter, you’ll need to specify --gerrit-projects for
your gerrit projects, and also --cookiefile for the gerrit auth token (leave it unset for anonymous).
Gerrit reporter will send an aggregated summary message, when all gerrit adapter
scheduled prowjobs with the same report label finish on a revision.
It will also attach a report url so people can find logs of the job.
The reporter will also cast a +1/-1 vote on the prow.k8s.io/gerrit-report-label label of your prowjob,
or by default it will vote on CodeReview label. Where +1 means all jobs on the patshset pass and -1
means one or more jobs failed on the patchset.
You can enable pubsub reporter in crier by specifying --pubsub-workers=n flag.
You need to specify following labels in order for pubsub reporter to report your prowjob:
| Label |
Description |
"prow.k8s.io/pubsub.project" |
Your gcp project where pubsub channel lives |
"prow.k8s.io/pubsub.topic" |
The topic of your pubsub message |
"prow.k8s.io/pubsub.runID" |
A user assigned job id. It’s tied to the prowjob, serves as a name tag and help user to differentiate results in multiple pubsub messages |
The service account used by crier will need to have pubsub.topics.publish permission in the project where pubsub channel lives, e.g. by assigning the roles/pubsub.publisher IAM role
Pubsub reporter will report whenever prowjob has a state transition.
You can check the reported result by list the pubsub topic.
You can enable github reporter in crier by specifying --github-workers=N flag (N>0).
You also need to mount a github oauth token by specifying --github-token-path flag, which defaults to /etc/github/oauth.
If you have a ghproxy deployed, also remember to point --github-endpoint to your ghproxy to avoid token throttle.
The actual report logic is in the github report library for your reference.
NOTE: if enabling the slack reporter for the first time, Crier will message to the Slack channel for all ProwJobs matching the configured filtering criteria.
You can enable the Slack reporter in crier by specifying the --slack-workers=n and --slack-token-file=path-to-tokenfile flags.
The --slack-token-file flag takes a path to a file containing a Slack OAuth Access Token.
The OAuth Access Token can be obtained as follows:
- Navigate to: https://api.slack.com/apps.
- Click Create New App.
- Provide an App Name (e.g. Prow Slack Reporter) and Development Slack Workspace (e.g. Kubernetes).
- Click Permissions.
- Add the
chat:write.public scope using the Scopes / Bot Token Scopes dropdown and Save Changes.
- Click Install App to Workspace
- Click Allow to authorize the Oauth scopes.
- Copy the OAuth Access Token.
Once the access token is obtained, you can create a secret in the cluster using that value:
kubectl create secret generic slack-token --from-literal=token=< access token >
Furthermore, to make this token available to Crier, mount the slack-token secret using a volume and set the --slack-token-file flag in the deployment spec.
apiVersion: apps/v1
kind: Deployment
metadata:
name: crier
labels:
app: crier
spec:
selector:
matchLabels:
app: crier
template:
metadata:
labels:
app: crier
spec:
containers:
- name: crier
image: gcr.io/k8s-prow/crier:v20200205-656133e91
args:
- --slack-workers=1
- --slack-token-file=/etc/slack/token
- --config-path=/etc/config/config.yaml
- --dry-run=false
volumeMounts:
- mountPath: /etc/config
name: config
readOnly: true
- name: slack
mountPath: /etc/slack
readOnly: true
volumes:
- name: slack
secret:
secretName: slack-token
- name: config
configMap:
name: config
Additionally, in order for it to work with Prow you must add the following to your config.yaml:
NOTE: slack_reporter_configs is a map of org, org/repo, or * (i.e. catch-all wildcard) to a set of slack reporter configs.
slack_reporter_configs:
# Wildcard (i.e. catch-all) slack config
"*":
# default: None
job_types_to_report:
- presubmit
- postsubmit
# default: None
job_states_to_report:
- failure
- error
# required
channel: my-slack-channel
# The template shown below is the default
report_template: "Job {{.Spec.Job}} of type {{.Spec.Type}} ended with state {{.Status.State}}. <{{.Status.URL}}|View logs>"
# "org/repo" slack config
istio/proxy:
job_types_to_report:
- presubmit
job_states_to_report:
- error
channel: istio-proxy-channel
# "org" slack config
istio:
job_types_to_report:
- periodic
job_states_to_report:
- failure
channel: istio-channel
The channel, job_states_to_report and report_template can be overridden at the ProwJob level via the reporter_config.slack field:
postsubmits:
some-org/some-repo:
- name: example-job
decorate: true
reporter_config:
slack:
channel: 'override-channel-name'
job_states_to_report:
- success
report_template: "Overridden template for job {{.Spec.Job}}"
spec:
containers:
- image: alpine
command:
- echo
To silence notifications at the ProwJob level you can pass an empty slice to reporter_config.slack.job_states_to_report:
postsubmits:
some-org/some-repo:
- name: example-job
decorate: true
reporter_config:
slack:
job_states_to_report: []
spec:
containers:
- image: alpine
command:
- echo
Implementation details
Crier supports multiple reporters, each reporter will become a crier controller. Controllers
will get prowjob change notifications from a shared informer, and you can specify --num-workers to change parallelism.
If you are interested in how client-go works under the hood, the details are explained
in this doc
Adding a new reporter
Each crier controller takes in a reporter.
Each reporter will implement the following interface:
type reportClient interface {
Report(pj *v1.ProwJob) error
GetName() string
ShouldReport(pj *v1.ProwJob) bool
}
GetName will return the name of your reporter, the name will be used as a key when we store previous
reported state for each prowjob.
ShouldReport will return if a prowjob should be handled by current reporter.
Report is the actual report logic happens. Return nil means report is successful, and the reported
state will be saved in the prowjob. Return an actual error if report fails, crier will re-add the prowjob
key to the shared cache and retry up to 5 times.
You can add a reporter that implements the above interface, and add a flag to turn it on/off in crier.
Migration from plank for github report
Both plank and crier will call into the github report lib when a prowjob needs to be reported,
so as a user you only want to make one of them to report :-)
To disable GitHub reporting in Plank, add the --skip-report=true flag to the Plank deployment.
Before migrating, be sure plank is setting the PrevReportStates field
by describing a finished presubmit prowjob. Plank started to set this field after commit 2118178, if not, you want to upgrade your plank to a version includes this commit before moving forward.
you can check this entry by:
$ kubectl get prowjobs -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.prev_report_states.github-reporter}{"\n"}'
...
fafec9e1-3af2-11e9-ad1a-0a580a6c0d12 failure
fb027a97-3af2-11e9-ad1a-0a580a6c0d12 success
fb0499d3-3af2-11e9-ad1a-0a580a6c0d12 failure
fb05935f-3b2b-11e9-ad1a-0a580a6c0d12 success
fb05e1f1-3af2-11e9-ad1a-0a580a6c0d12 error
fb06c55c-3af2-11e9-ad1a-0a580a6c0d12 success
fb09e7d8-3abb-11e9-816a-0a580a6c0f7f success
You want to add a crier deployment, similar to ours config/prow/cluster/crier_deployment.yaml,
flags need to be specified:
- point
config-path and --job-config-path to your prow config and job configs accordingly.
- Set
--github-worker to be number of parallel github reporting threads you need
- Point
--github-endpoint to ghproxy, if you have set that for plank
- Bind github oauth token as a secret and set
--github-token-path if you’ve have that set for plank.
In your plank deployment, you can
- Remove the
--github-endpoint flags
- Remove the github oauth secret, and
--github-token-path flag if set
- Flip on
--skip-report, so plank will skip the reporting logic
Both change should be deployed at the same time, if have an order preference, deploy crier first since report twice should just be a no-op.
We will send out an announcement when we cleaning up the report dependency from plank in later 2019.
1.2 - Deck
Shows what jobs are running or have recently run in prow
Running Deck locally
Deck can be run locally by executing ./prow/cmd/deck/runlocal. The scripts starts Deck via
Bazel using:
- pre-generated data (extracted from a running Prow instance)
- the local
config.yaml
- the local static files, template files and lenses
Open your browser and go to: http://localhost:8080
Debugging via Intellij / VSCode
This section describes how to debug Deck locally by running it inside
VSCode or Intellij.
# Prepare assets
make -C prow build-tarball PROW_IMAGE=prow/cmd/deck
mkdir -p /tmp/deck
tar -xvf ./_bin/deck.tar -C /tmp/deck
cd /tmp/deck
# Expand all layers
for tar in *.tar.gz; do tar -xvf $tar; done
# Start Deck via go or in your IDE with the following arguments:
--config-path=./config/prow/config.yaml
--job-config-path=./config/jobs
--hook-url=http://prow.k8s.io
--spyglass
--template-files-location=/tmp/deck/var/run/ko/template
--static-files-location=/tmp/deck/var/run/ko/static
--spyglass-files-location=/tmp/deck/var/run/ko/lenses
Rerun Prow Job via Prow UI
Rerun prow job can be done by visiting prow UI, locate prow job and rerun job by clicking on the ↻ button, selecting a configuration option, and then clicking Rerun button. For prow on github, the permission is controlled by github membership, and configured as part of deck configuration, see rerun_auth_configs for k8s prow.
See example below:

Rerunning can also be done on Spyglass:

This is also available for non github prow if the frontend is secured and allow_anyone is set to true for the job.
Abort Prow Job via Prow UI
Aborting a prow job can be done by visiting the prow UI, locate the prow job and abort the job by clicking on the ✕ button, and then clicking Confirm button. For prow on github, the permission is controlled by github membership, and configured as part of deck configuration, see rerun_auth_configs for k8s prow. Note, the abort functionality uses the same field as rerun for permissions.
See example below:

Aborting can also be done on Spyglass:

This is also available for non github prow if the frontend is secured and allow_anyone is set to true for the job.
1.2.1 - How to setup GitHub Oauth
This document helps configure GitHub Oauth, which is required for PR Status
and for the rerun button on Prow Status.
If OAuth is configured, Prow will perform GitHub actions on behalf of the authenticated users.
This is necessary to fetch information about pull requests for the PR Status page and to
authenticate users when checking if they have permission to rerun jobs via the rerun button on Prow Status.
Set up secrets
The following steps will show you how to set up an OAuth app.
-
Create your GitHub Oauth application
https://developer.github.com/apps/building-oauth-apps/creating-an-oauth-app/
Make sure to create a GitHub Oauth App and not a regular GitHub App.
The callback url should be:
<PROW_BASE_URL>/github-login/redirect
-
Create a secret file for GitHub OAuth that has the following content. The information can be found in the GitHub OAuth developer settings:
client_id: <APP_CLIENT_ID>
client_secret: <APP_CLIENT_SECRET>
redirect_url: <PROW_BASE_URL>/github-login/redirect
final_redirect_url: <PROW_BASE_URL>/pr
If Prow is expected to work with private repositories, add
-
Create another secret file for the cookie store. This cookie secret will also be used for CSRF protection.
The file should contain a random 32-byte length base64 key. For example, you can use openssl to generate the key
openssl rand -out cookie.txt -base64 32
-
Use kubectl, which should already point to your Prow cluster, to create secrets using the command:
kubectl create secret generic github-oauth-config --from-file=secret=<PATH_TO_YOUR_GITHUB_SECRET>
kubectl create secret generic cookie --from-file=secret=<PATH_TO_YOUR_COOKIE_KEY_SECRET>
-
To use the secrets, you can either:
-
Mount secrets to your deck volume:
Open test-infra/config/prow/cluster/deck_deployment.yaml.
Under volumes token, add:
- name: oauth-config
secret:
secretName: github-oauth-config
- name: cookie-secret
secret:
secretName: cookie
Under volumeMounts token, add:
- name: oauth-config
mountPath: /etc/githuboauth
readOnly: true
- name: cookie-secret
mountPath: /etc/cookie
readOnly: true
-
Add the following flags to deck:
- --github-oauth-config-file=/etc/githuboauth/secret
- --oauth-url=/github-login
- --cookie-secret=/etc/cookie/secret
Note that the --oauth-url should eventually be changed to a boolean as described
in #13804.
-
You can also set your own path to the cookie secret using the --cookie-secret flag.
-
To prevent deck from making mutating GitHub API calls, pass in the --dry-run flag.
Using A GitHub bot
The rerun button can be configured so that certain GitHub teams are allowed to trigger certain jobs
from the frontend. In order to make API calls to determine whether a user is on a given team, deck needs
to use the access token of an org member.
If not, you can create a new GitHub account, make it an org member, and set up a personal access token
here.
Then create the access token secret:
kubectl create secret generic oauth-token --from-file=secret=<PATH_TO_ACCESS_TOKEN>
Add the following to volumes and volumeMounts:
volumeMounts:
- name: oauth-token
mountPath: /etc/github
readOnly: true
volumes:
- name: oauth-token
secret:
secretName: oauth-token
Pass the file path to deck as a flag:
--github-token-path=/etc/github/oauth
You can optionally use ghproxy to reduce token usage.
Run PR Status endpoint locally
Firstly, you will need a GitHub OAuth app. Please visit step 1 - 3 above.
When testing locally, pass the path to your secrets to deck using the --github-oauth-config-file and --cookie-secret flags.
Run the command:
go build . && ./deck --config-path=../../../config/prow/config.yaml --github-oauth-config-file=<PATH_TO_YOUR_GITHUB_OAUTH_SECRET> --cookie-secret=<PATH_TO_YOUR_COOKIE_SECRET> --oauth-url=/pr
Using a test cluster
If hosting your test instance on http instead of https, you will need to use the --allow-insecure flag in deck.
1.2.2 - CSRF attacks
In Deck, we make a number of POST requests that require user authentication. These requests are susceptible
to cross site request forgery (CSRF) attacks,
in which a malicious actor tricks an already authenticated user into submitting a form to one of these endpoints
and performing one of these protected actions on their behalf.
Protection
If --cookie-secret is 32 or more bytes long, CSRF protection is automatically enabled.
If --rerun-creates-job is specified, CSRF protection is required, and accordingly,
--cookie-secret must be 32 bytes long.
We protect against CSRF attacks using the gorilla CSRF library, implemented
in #13323. Broadly, this protection works by ensuring that
any POST request originates from our site, rather than from an outside link.
We do so by requiring that every POST request made to Deck includes a secret token either in the request header
or in the form itself as a hidden input.
We cryptographically generate the CSRF token using the --cookie-secret and a user session value and
include it as a header in every POST request made from Deck.
If you are adding a new POST request, you must include the CSRF token as described in the gorilla
documentation.
The gorilla library expects a 32-byte CSRF token. If --cookie-secret is sufficiently long,
direct job reruns will be enabled via the /rerun endpoint. Otherwise, if --cookie-secret is less
than 32 bytes and --rerun-creates-job is enabled, Deck will refuse to start. Longer values will
work but should be truncated.
By default, gorilla CSRF requires that all POST requests are made over HTTPS. If developing locally
over HTTP, you must specify --allow-insecure to Deck, which will configure both gorilla CSRF
and GitHub oauth to allow HTTP requests.
CSRF can also be executed by tricking a user into making a state-mutating GET request. All
state-mutating requests must therefore be POST requests, as gorilla CSRF does not secure GET
requests.
1.3 - Hook
This is a placeholder page. Some contents needs to be filled.
1.4 - Horologium
This is a placeholder page. Some contents needs to be filled.
1.5 - Prow-Controller-Manager
prow-controller-manager manages the job execution and lifecycle for jobs running in k8s.
It currently acts as a replacement for Plank.
It is intended to eventually replace other components, such as Sinker and Crier.
See the tracking issue #17024 for details.
Advantages
- Eventbased rather than cronbased, hence reacting much faster to changes in prowjobs or pods
- Per-Prowjob retrying, meaning genuinely broken prowjobs will not be retried forever and transient errors will be retried much quicker
- Uses a cache for the build cluster rather than doing a LIST every 30 seconds, reducing the load on the build clusters api server
Exclusion with other components
This is mutually exclusive with only Plank.
Only one of them may have more than zero replicas at the same time.
Usage
$ go run ./prow/cmd/prow-controller-manager --help
Configuration
1.6 - Sinker
This is a placeholder page. Some contents needs to be filled.
1.7 - Tide
Tide is a Prow
component for managing a pool of GitHub PRs that match a given set of criteria.
It will automatically retest PRs that meet the criteria (“tide comes in”) and automatically merge
them when they have up-to-date passing test results (“tide goes out”).
Open Issues
Documentation
Features
- Automatically runs batch tests and merges multiple PRs together whenever possible.
- Ensures that PRs are tested against the most recent base branch commit before they are allowed to merge.
- Maintains a GitHub status context that indicates if each PR is in a pool or what requirements are missing.
- Supports blocking merge to individual branches or whole repos using specifically labelled GitHub issues.
- Exposes Prometheus metrics.
- Supports repos that have ‘optional’ status contexts that shouldn’t be required for merge.
- Serves live data about current pools and a history of actions which can be consumed by Deck to populate the Tide dashboard, the PR dashboard, and the Tide history page.
- Scales efficiently so that a single instance with a single bot token can provide merge automation to dozens of orgs and repos with unique merge criteria. Every distinct ‘org/repo:branch’ combination defines a disjoint merge pool so that merges only affect other PRs in the same branch.
- Provides configurable merge modes (‘merge’, ‘squash’, or ‘rebase’).
History
Tide was created in 2017 by @spxtr to replace mungegithub’s Submit Queue. It was designed to manage a large number of repositories across organizations without using many API rate limit tokens by identifying mergeable PRs with GitHub search queries fulfilled by GitHub’s v4 GraphQL API.
Flowchart
graph TD;
subgraph github[GitHub]
subgraph org/repo/branch
head-ref[HEAD ref];
pullrequest[Pull Request];
status-context[Status Context];
end
end
subgraph prow-cluster
prowjobs[Prowjobs];
config.yaml;
end
subgraph tide-workflow
Tide;
pools;
divided-pools;
pools-->|dividePool|divided-pools;
filtered-pools;
subgraph syncSubpool
pool-i;
pool-n;
pool-n1;
accumulated-batch-prowjobs-->|filter out <br> incorrect refs <br> no longer meet merge requirement|valid-batches;
valid-batches-->accumulated-batch-success;
valid-batches-->accumulated-batch-pending;
status-context-->|fake prowjob from context|filtered-prowjobs;
filtered-prowjobs-->|accumulate|map_context_best-result;
map_context_best-result-->map_pr_overall-results;
map_pr_overall-results-->accumulated-success;
map_pr_overall-results-->accumulated-pending;
map_pr_overall-results-->accumulated-stale;
subgraph all-accumulated-pools
accumulated-batch-success;
accumulated-batch-pending;
accumulated-success;
accumulated-pending;
accumulated-stale;
end
accumulated-batch-success-..->accumulated-batch-success-exist{Exist};
accumulated-batch-pending-..->accumulated-batch-pending-exist{Exist};
accumulated-success-..->accumulated-success-exist{Exist};
accumulated-pending-..->accumulated-pending-exist{Exist};
accumulated-stale-..->accumulated-stale-exist{Exist};
pool-i-..->require-presubmits{Require Presubmits};
accumulated-batch-success-exist-->|yes|merge-batch[Merge batch];
merge-batch-->|Merge Pullrequests|pullrequest;
accumulated-batch-success-exist-->|no|accumulated-batch-pending-exist;
accumulated-batch-pending-exist-->|no|accumulated-success-exist;
accumulated-success-exist-->|yes|merge-single[Merge Single];
merge-single-->|Merge Pullrequests|pullrequest;
require-presubmits-->|no|wait;
accumulated-success-exist-->|no|require-presubmits;
require-presubmits-->|yes|accumulated-pending-exist;
accumulated-pending-exist-->|no|can-trigger-batch{Can Trigger New Batch};
can-trigger-batch-->|yes|trigger-batch[Trigger new batch];
can-trigger-batch-->|no|accumulated-stale-exist;
accumulated-stale-exist-->|yes|trigger-highest-pr[Trigger Jobs on Highest Priority PR];
accumulated-stale-exist-->|no|wait;
end
end
Tide-->pools[Pools - grouped PRs, prow jobs by org/repo/branch];
pullrequest-->pools;
divided-pools-->|filter out prs <br> failed prow jobs <br> pending non prow checks <br> merge conflict <br> invalid merge method|filtered-pools;
head-ref-->divided-pools;
prowjobs-->divided-pools;
config.yaml-->divided-pools;
filtered-pools-->pool-i;
filtered-pools-->pool-n;
filtered-pools-->pool-n1[pool ...];
pool-i-->|report tide status|status-context;
pool-i-->|accumulateBatch|accumulated-batch-prowjobs;
pool-i-->|accumulateSerial|filtered-prowjobs;
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef github fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
classDef pools-def fill:#00ffff,stroke:#bbb,stroke-width:2px,color:#326ce5;
classDef decision fill:#ffff00,stroke:#bbb,stroke-width:2px,color:#326ce5;
classDef outcome fill:#00cc66,stroke:#bbb,stroke-width:2px,color:#326ce5;
class prowjobs,config.yaml k8s;
class Tide plain;
class status-context,head-ref,pullrequest github;
class accumulated-batch-success,accumulated-batch-pending,accumulated-success,accumulated-pending,accumulated-stale pools-def;
class accumulated-batch-success-exist,accumulated-batch-pending-exist,accumulated-success-exist,accumulated-pending-exist,accumulated-stale-exist,can-trigger-batch,require-presubmits decision;
class trigger-highest-pr,trigger-batch,merge-single,merge-batch,wait outcome;
1.7.1 - Configuring Tide
Configuration of Tide is located under the config/prow/config.yaml file. All configuration for merge behavior and criteria belongs in the tide yaml struct, but it may be necessary to also configure presubmits for Tide to run against PRs (see ‘Configuring Presubmit Jobs’ below).
This document will describe the fields of the tide configuration and how to populate them, but you can also check out the GoDocs for the most up to date configuration specification.
To deploy Tide for your organization or repository, please see how to get started with prow.
General configuration
The following configuration fields are available:
sync_period: The field specifies how often Tide will sync jobs with GitHub. Defaults to 1m.status_update_period: The field specifies how often Tide will update GitHub status contexts.
Defaults to the value of sync_period.queries: List of queries (described below).merge_method: A key/value pair of an org/repo as the key and merge method to override
the default method of merge as value. Valid options are squash, rebase, and merge.
Defaults to merge.merge_commit_template: A mapping from org/repo or org to a set of Go templates to use when creating the title and body of merge commits. Go templates are evaluated with a PullRequest (see PullRequest type). This field and map keys are optional.target_urls: A mapping from “*”, , or <org/repo> to the URL for the tide status contexts. The most specific key that matches will be used.pr_status_base_urls: A mapping from “*”, , or <org/repo> to the base URL for the PR status page. If specified, this URL is used to construct
a link that will be used for the tide status context. It is mutually exclusive with the target_urls field.max_goroutines: The maximum number of goroutines spawned inside the component to
handle org/repo:branch pools. Defaults to 20. Needs to be a positive number.blocker_label: The label used to identify issues which block merges to repository branches.squash_label: The label used to ask Tide to use the squash method when merging the labeled PR.rebase_label: The label used to ask Tide to use the rebase method when merging the labeled PR.merge_label: The label used to ask Tide to use the merge method when merging the labeled PR.
Merge Blocker Issues
Tide supports temporary holds on merging into branches via the blocker_label configuration option.
In order to use this option, set the blocker_label configuration option for the Tide deployment.
Then, when blocking merges is required, if an open issue is found with the label it will block merges to
all branches for the repo. In order to scope the branches which are blocked, add a branch:name token
to the issue title. These tokens can be repeated to select multiple branches and the tokens also support
quoting, so branch:"name" will block the name branch just as branch:name would.
Queries
The queries field specifies a list of queries.
Each query corresponds to a set of open PRs as candidates for merging.
It can consist of the following dictionary of fields:
orgs: List of queried organizations.repos: List of queried repositories.excludedRepos: List of ignored repositories.labels: List of labels any given PR must posses.missingLabels: List of labels any given PR must not posses.excludedBranches: List of branches that get excluded when querying the repos.includedBranches: List of branches that get included when querying the repos.author: The author of the PR.reviewApprovedRequired: If set, each PR in the query must have at
least one approved GitHub pull request
review
present for merge. Defaults to false.
Under the hood, a query constructed from the fields follows rules described in
https://help.github.com/articles/searching-issues-and-pull-requests/.
Therefore every query is just a structured definition of a standard GitHub
search query which can be used to list mergeable PRs.
The field to search token correspondence is based on the following mapping:
orgs -> org:kubernetesrepos -> repo:kubernetes/test-infralabels -> label:lgtmmissingLabels -> -label:do-not-mergeexcludedBranches -> -base:devincludedBranches -> base:masterauthor -> author:batmanreviewApprovedRequired -> review:approved
Every PR that needs to be rebased or is failing required statuses is filtered from the pool before processing
Context Policy Options
A PR will be merged when all checks are passing. With this option you can customize
which contexts are required or optional.
By default, required and optional contexts will be derived from Prow Job Config.
This allows to find if required checks are missing from the GitHub combined status.
If branch-protection config is defined, it can be used to know which test needs
be passing to merge a PR.
When branch protection is not used, required and optional contexts can be defined
globally, or at the org, repo or branch level.
If we want to skip unknown checks (ie checks that are not defined in Prow Config), we can set
skip-unknown-contexts to true. This option can be set globally or per org,
repo and branch.
Important: If this option is not set and no prow jobs are defined tide will trust the GitHub
combined status and will assume that all checks are required (except for it’s own tide status).
Example
tide:
merge_method:
kubeflow/community: squash
target_url: https://prow.k8s.io/tide
queries:
- repos:
- kubeflow/community
- kubeflow/examples
labels:
- lgtm
- approved
missingLabels:
- do-not-merge
- do-not-merge/hold
- do-not-merge/work-in-progress
- needs-ok-to-test
- needs-rebase
context_options:
# Use branch-protection options from this file to define required and optional contexts.
# this is convenient if you are using branchprotector to configure branch protection rules
# as tide will use the same rules as will be added by the branch protector
from-branch-protection: true
# Specify how to handle contexts that are detected on a PR but not explicitly listed in required-contexts,
# optional-contexts, or required-if-present-contexts. If true, they are treated as optional and do not
# block a merge. If false or not present, they are treated as required and will block a merge.
skip-unknown-contexts: true
orgs:
org:
required-contexts:
- "check-required-for-all-repos"
repos:
repo:
required-contexts:
- "check-required-for-all-branches"
branches:
branch:
from-branch-protection: false
required-contexts:
- "required_test"
optional-contexts:
- "optional_test"
required-if-present-contexts:
- "conditional_test"
Explanation: The component starts periodically querying all PRs in github.com/kubeflow/community and
github.com/kubeflow/examples repositories that have lgtm and approved labels set
and do not have do-not-merge, do-not-merge/hold, do-not-merge/work-in-progress, needs-ok-to-test and needs-rebase labels set.
All PRs that conform to the criteria are processed and merged.
The processing itself can include running jobs (e.g. tests) to verify the PRs are good to go.
All commits in PRs from github.com/kubeflow/community repository are squashed before merging.
For a full list of properties of queries, please refer to https://github.com/kubernetes/test-infra/blob/27c9a7f2784088c2db5ff133e8a7a1e2eab9ab3f/prow/config/prow-config-documented.yaml#:~:text=meet%20merge%20requirements.-,queries%3A,-%2D%20author%3A%20%27%20%27.
Persistent Storage of Action History
Tide records a history of the actions it takes (namely triggering tests and merging).
This history is stored in memory, but can be loaded from GCS and periodically flushed
in order to persist across pod restarts. Persisting action history to GCS is strictly
optional, but is nice to have if the Tide instance is restarted frequently or if
users want to view older history.
Both the --history-uri and --gcs-credentials-file flags must be specified to Tide
to persist history to GCS. The GCS credentials file should be a GCP service account
key file
for a service account that has permission to read and write the history GCS object.
The history URI is the GCS object path at which the history data is stored. It should
not be publicly readable if any repos are sensitive and must be a GCS URI like gs://bucket/path/to/object.
Example
Configuring Presubmit Jobs
Before a PR is merged, Tide ensures that all jobs configured as required in the presubmits part of the config.yaml file are passing against the latest base branch commit, rerunning the jobs if necessary. No job is required to be configured in which case it’s enough if a PR meets all GitHub search criteria.
Semantic of individual fields of the presubmits is described in ProwJobs.
1.7.2 - Maintainer's Guide to Tide
Best practices
- Don’t let humans (or other bots) merge especially if tests have a long duration. Every merge invalidates currently running tests for that pool.
- Try to limit the total number of queries that you configure. Individual queries can cover many repos and include many criteria without using additional API tokens, but separate queries each require additional API tokens.
- Ensure that merge requirements configured in GitHub match the merge requirements configured for Tide. If the requirements differ, Tide may try to merge a PR that GitHub considers unmergeable.
- If you are using the
lgtm plugin and requiring the lgtm label for merge, don’t make queries exclude the needs-ok-to-test label. The lgtm plugin triggers one round of testing when applied to an untrusted PR and removes the lgtm label if the PR changes so it indicates to Tide that the current version of the PR is considered trusted and can be retested safely.
- Do not enable the “Require branches to be up to date before merging” GitHub setting for repos managed by Tide. This requires all PRs to be rebased before merge so that PRs are always simple fast-forwards. This is a simplistic way to ensure that PRs are tested against the most recent base branch commit, but Tide already provides this guarantee through a more sophisticated mechanism that does not force PR authors to rebase their PR whenever another PR merges first. Enabling this GH setting may cause unexpected Tide behavior, provides absolutely no benefit over Tide’s natural behavior, and forces PR author’s to needlessly rebase their PRs. Don’t use it on Tide managed repos.
Expected behavior that might seem strange
- Any merge to a pool kicks all other PRs in the pool back into
Queued for retest. This is because Tide requires PRs to be tested against the most recent base branch commit in order to be merged. When a merge occurs, the base branch updates so any existing or in-progress tests can no longer be used to qualify PRs for merge. All remaining PRs in the pool must be retested.
- Waiting to merge a successful PR because a batch is pending. This is because Tide prioritizes batches over individual PRs and the previous point tells us that merging the individual PR would invalidate the pending batch. In this case Tide will wait for the batch to complete and will merge the individual PR only if the batch fails. If the batch succeeds, the batch is merged.
- If the merge requirements for a pool change it may be necessary to “poke” or “bump” PRs to trigger an update on the PRs so that Tide will resync the status context. Alternatively, Tide can be restarted to resync all statuses.
- Tide may merge a PR without retesting if the existing test results are already against the latest base branch commit.
- It is possible for
tide status contexts on PRs to temporarily differ from the Tide dashboard or Tide’s behavior. This is because status contexts are updated asynchronously from the main Tide sync loop and have a separate rate limit and loop period.
Troubleshooting
- If Prow’s PR dashboard indicates that a PR is ready to merge and it appears to meet all merge requirements, but the PR is being ignored by Tide, you may have encountered a rare bug with GitHub’s search indexing. TLDR: If this is the problem, then any update to the PR (e.g. adding a comment) will make the PR visible to Tide again after a short delay.
The longer explanation is that when GitHub’s background jobs for search indexing PRs fail, the search index becomes corrupted and the search API will have some incorrect belief about the affected PR, e.g. that it is missing a required label or still has a forbidden one. This causes the search query Tide uses to identify the mergeable PRs to incorrectly omit the PR. Since the same search engine is used by both the API and GitHub’s front end, you can confirm that the affected PR is not included in the query for mergeable PRs by using the appropriate “GitHub search link” from the expandable “Merge Requirements” section on the Tide status page. You can actually determine which particular index is corrupted by incrementally tweaking the query to remove requirements until the PR is included.
Any update to the PR causes GitHub to kick off a new search indexing job in the background. Once it completes, the corrupted index should be fixed and Tide will be able to see the PR again in query results, allowing Tide to resume processing the PR. It appears any update to the PR is sufficient to trigger reindexing so we typically just leave a comment. Slack thread about an example of this.
Other resources
1.7.3 - PR Author's Guide to Tide
If you just want to figure out how to get your PR to merge this is the document for you!
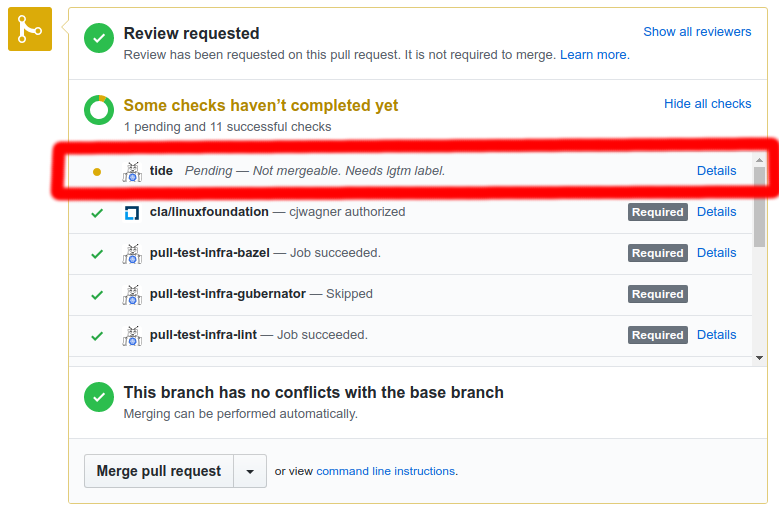
- The
tide status context at the bottom of your PR.
The status either indicates that your PR is in the merge pool or explains why it is not in the merge pool. The ‘Details’ link will take you to either the Tide or PR dashboard.
- The PR dashboard at “
<deck-url>/pr” where <deck-url> is something like “https://prow.k8s.io”.
This dashboard shows a card for each of your PRs. Each card shows the current test results for the PR and the difference between the PR state and the merge criteria. K8s PR dashboard
- The Tide dashboard at “
<deck-url>/tide”.
This dashboard shows the state of every merge pool so that you can see what Tide is currently doing and what position your PR has in the retest queue. K8s Tide dashboard
Get your PR merged by asking these questions
“Is my PR in the merge pool?”
If the tide status at the bottom of your PR is successful (green) it is in the merge pool. If it is pending (yellow) it is not in the merge pool.
“Why is my PR not in the merge pool?”
First, if you just made a change to the PR, give Tide a minute or two to react. Tide syncs periodically (1m period default) so you shouldn’t expect to see immediate reactions.
To determine why your PR is not in the merge pool you have a couple options.
- The
tide status context at the bottom of your PR will describe at least one of the merge criteria that is not being met. The status has limited space for text so only a few failing criteria can typically be listed. To see all merge criteria that are not being met check out the PR dashboard.
- The PR dashboard shows the difference between your PR’s state and the merge criteria so that you can easily see all criteria that are not being met and address them in any order or in parallel.
“My PR is in the merge pool, what now?”
Once your PR is in the merge pool it is queued for merge and will be automatically retested before merge if necessary. So typically your work is done!
The one exception is if your PR fails a retest. This will cause the PR to be removed from the merge pool until it is fixed and is passing all the required tests again.
If you are eager for your PR to merge you can view all the PRs in the pool on the Tide dashboard to see where your PR is in the queue. Because we give older PRs (lower numbers) priority, it is possible for a PR’s position in the queue to increase.
Note: Batches of PRs are given priority over individual PRs so even if your PR is in the pool and has up-to-date tests it won’t merge while a batch is running because merging would update the base branch making the batch jobs stale before they complete.
Similarly, whenever any other PR in the pool is merged, existing test results for your PR become stale and a retest becomes necessary before merge. However, your PR remains in the pool and will be automatically retested so this doesn’t require any action from you.
2 - Optional Components
2.1 - Branchprotector
branchprotector configures github branch protection according to a specified
policy.
Policy configuration
Extend the primary prow config.yaml document to include a top-level
branch-protection key that looks like the following:
branch-protection:
orgs:
kubernetes:
repos:
test-infra:
# Protect all branches in kubernetes/test-infra
protect: true
# Always allow the org's oncall-team to push
restrictions:
teams: ["oncall-team"]
# Ensure that the extra-process-followed github status context passes.
# In addition, adds any required prow jobs (aka always_run: true)
required_status_checks:
contexts: ["extra-process-followed"]
presubmits:
kubernetes/test-infra:
- name: fancy-job-name
context: fancy-job-name
always_run: true
spec: # podspec that runs job
This config will:
- Enable protection for every branch in the
kubernetes/test-infra
repo.
- Require
extra-process-followed and fancy-job-name status contexts to pass
before allowing a merge
- Although it will always allow
oncall-team to merge, even if required
contexts fail.
- Note that
fancy-job-name is pulled in automatically from the
presubmits config for the repo, if one exists.
Updating
- Send PR with
config.yaml changes
- Merge PR
- Done!
Make changes to the policy by modifying config.yaml in your favorite text
editor and then send out a PR. When the PR merges prow pushes the updated config
. The branchprotector applies the new policies the next time it runs (within
24hrs).
Advanced configuration
Fields
See branch_protection.go and GitHub’s protection api for a complete list of fields allowed
inside branch-protection and their meanings. The format is:
branch-protection:
# default policy here
orgs:
foo:
# this is the foo org policy
protect: true # enable protection
enforce_admins: true # rules apply to admins
required_linear_history: true # enforces a linear commit Git history
allow_force_pushes: true # permits force pushes to the protected branch
allow_deletions: true # allows deletion of the protected branch
required_pull_request_reviews:
dismiss_stale_reviews: false # automatically dismiss old reviews
dismissal_restrictions: # allow review dismissals
users:
- her
- him
teams:
- them
- those
require_code_owner_reviews: true # require a code owner approval
required_approving_review_count: 1 # number of approvals
required_status_checks:
strict: false # require pr branch to be up to date
contexts: # checks which must be green to merge
- foo
- bar
restrictions: # restrict who can push to the repo
apps:
- github-prow-app
users:
- her
- him
teams:
- them
- those
Scope
It is possible to define a policy at the
branch-protection, org, repo or branch level. For example:
branch-protection:
# Protect unless overridden
protect: true
# If protected, always require the cla status context
required_status_checks:
contexts: ["cla"]
orgs:
unprotected-org:
# Disable protection unless overridden (overrides parent setting of true)
protect: false
repos:
protected-repo:
protect: true
# Inherit protect-by-default config from parent
# If protected, always require the tested status context
required_status_checks:
contexts: ["tested"]
branches:
secure:
# Protect the secure branch (overrides inhereted parent setting of false)
protect: true
# Require the foo status context
required_status_checks:
contexts: ["foo"]
different-org:
# Inherits protect-by-default: true setting from above
The general rule for how to compute child values is:
- If the child value is
null or missing, inherit the parent value.
- Otherwise:
- List values (like
contexts), create a union of the parent and child lists.
- For bool/int values (like
protect), the child value replaces the parent value.
So in the example above:
- The
secure branch in unprotected-org/protected-repo
- enables protection (set a branch level)
- requires
foo tested cla status contexts
(the latter two are appended by ancestors)
- All other branches in
unprotected-org/protected-repo
- disable protection (inherited from org level)
- All branches in all other repos in
unprotected-org
- disable protection (set at org level)
- All branches in all repos in
different-org
- Enable protection (inherited from branch-protection level)
- Require the
cla context to be green to merge (appended by parent)
Developer docs
Run unit tests
go test ./prow/cmd/branchprotector
Run locally
go run ./prow/cmd/branchprotector --help, which will tell you about the
current flags.
Do a dry run (which will not make any changes to github) with
something like the following command:
go run ./prow/cmd/branchprotector \
--config-path=/path/to/config.yaml \
--github-token-path=/path/to/my-github-token
This will say how the binary will actually change github if you add a
--confirm flag.
Deploy local changes to dev cluster
Run things like the following:
# Build image locally
make -C prow push-single-image PROW_IMAGE=prow/cmd/branchprotector REGISTRY=<YOUR_REGISTRY>
This will build an image with your local changes, push it to <YOUR_REGISTRY>
Deploy cronjob to production
branchprotector image is automatically built
as part of prow, see
“How to update the cluster”
for more details.
Branchprotector runs as a prow periodic job, for example
ci-test-infra-branchprotector.
2.2 - Exporter
The prow-exporter exposes metrics about prow jobs while the
metrics are not directly related to a specific prow-component.
Metrics
| Metric name |
Metric type |
Labels/tags |
| prow_job_labels |
Gauge |
job_name=<prow_job-name>
job_namespace=<prow_job-namespace>
job_agent=<prow_job-agent>
label_PROW_JOB_LABEL_KEY=<PROW_JOB_LABEL_VALUE> |
| prow_job_annotations |
Gauge |
job_name=<prow_job-name>
job_namespace=<prow_job-namespace>
job_agent=<prow_job-agent>
annotation_PROW_JOB_ANNOTATION_KEY=<PROW_JOB_ANNOTATION_VALUE> |
| prow_job_runtime_seconds |
Histogram |
job_name=<prow_job-name>
job_namespace=<prow_job-namespace>
type=<prow_job-type>
last_state=<last-state>
state=<state>
org=<org>
repo=<repo>
base_ref=<base_ref>
|
For example, the metric prow_job_labels is similar to kube_pod_labels defined
in kubernetes/kube-state-metrics.
A typical usage of prow_job_labels is to join
it with other metrics using a Prometheus matching operator.
Note that job_name is .spec.job
instead of .metadata.name as taken in kube_pod_labels.
The gauge value is always 1 because we have another metric prowjobs
for the number jobs by name. The metric here shows only the existence of such a job with the label set in the cluster.
2.3 - gcsupload
gcsupload uploads artifacts to cloud storage at a path resolved from the job configuration.
gcsupload can be configured by either passing in flags or by specifying a full set of options
as JSON in the $GCSUPLOAD_OPTIONS environment variable, which has the following form:
{
"bucket": "kubernetes-jenkins",
"sub_dir": "",
"items": [
"/logs/artifacts/"
],
"path_strategy": "legacy",
"default_org": "kubernetes",
"default_repo": "kubernetes",
"gcs_credentials_file": "/secrets/gcs/service-account.json",
"dry_run": "false"
}
In addition to this configuration for the tool, the $JOB_SPEC environment variable should be
present to provide the contents of the Prow downward API for jobs. This data is used to resolve
the exact location in GCS to which artifacts and logs will be pushed.
The path strategy field can be one of "legacy", "single", and "explicit". This field
determines how the organization and repository of the code under test is encoded into the GCS path
for the test artifacts:
| Strategy |
Encoding |
"legacy" |
"" for the default org and repo, "org" for non-default repos in the default org, "org_repo" for repos in other orgs. |
"single" |
"" for the default org and repo, "org_repo" for all other repos. |
"explicit" |
"org_repo" for all repos. |
For historical reasons, the "legacy" or "single" strategies may already be in use for some;
however, for new deployments it is strongly advised to use the "explicit" strategy.
2.4 - Gerrit
Gerrit is a Prow-gerrit adapter for handling CI on gerrit workflows. It can poll gerrit
changes from multiple gerrit instances, and trigger presubmits on Prow upon new patchsets
on Gerrit changes, and postsubmits when Gerrit changes are merged.
Deployment Usage
When deploy the gerrit component, you need to specify --config-path to your prow config, and optionally
--job-config-path to your prowjob config if you have split them up.
Set --gerrit-projects to the gerrit projects you want to poll against.
Example:
If you want prow to interact with gerrit project foo and bar on instance gerrit-1.googlesource.com
and also project baz on instance gerrit-2.googlesource.com, then you can set:
--gerrit-projects=gerrit-1.googlesource.com=foo,bar
--gerrit-projects=gerrit-2.googlesource.com=baz
--cookiefile allows you to specify a git https cookie file to interact with your gerrit instances, leave
it empty for anonymous access to gerrit API.
--last-sync-fallback should point to a persistent volume that saves your last poll to gerrit.
Underlying infra
Also take a look at gerrit related packages for implementation details.
You might also want to deploy Crier which reports job results back to gerrit.
2.5 - HMAC
hmac is a tool to update the HMAC token, GitHub webhooks and HMAC secret
for the orgs/repos as per the managed_webhooks configuration changes in the Prow config file.
Prerequisites
To run this tool, you’ll need:
-
A github account that has admin permission to the orgs/repos.
-
A personal access token for the github account.
Note the token must be granted admin:repo_hook and admin:org_hook scopes.
-
Permissions to read&write the hmac secret in the Prow cluster.
There are two ways to run this tool:
- Run it on local:
go run ./prow/cmd/hmac \
--config-path=/path/to/prow/config \
--github-token-path=/path/to/oauth/secret \
--kubeconfig=/path/to/kubeconfig \
--kubeconfig-context=[context of the cluster to connect] \
--hmac-token-secret-name=[hmac secret name in Prow cluster] \
--hmac-token-key=[key of the hmac tokens in the secret] \
--hook-url http://an.ip.addr.ess/hook \
--dryrun=true # Remove it to actually update hmac tokens and webhooks
- Run it as a Prow job:
The recommended way to run this tool would be running it as a postsubmit job.
One example Prow job configured for k8s Prow can be found here.
How it works
Given a new managed_webhooks configuration in the Prow core config file,
the tool can reconcile the current state of HMAC tokens, secrets and
webhooks to meet the new configuration.
Configuration example
Below is a typical example for the managed_webhooks configuration:
managed_webhooks:
# Whether this tool should respect the legacy global token.
# This has to be true if any of the managed repo/org is using the legacy global token that is manually created.
respect_legacy_global_token: true
# Controls whether org/repo invitation for prow bot should be automatically
# accepted or not. Only admin level invitations related to orgs and repos
# in the managed_webhooks config will be accepted and all other invitations
# will be left pending.
auto_accept_invitation: true
# Config for orgs and repos that have been onboarded to this Prow instance.
org_repo_config:
qux:
token_created_after: 2017-10-02T15:00:00Z
foo/bar:
token_created_after: 2018-10-02T15:00:00Z
foo/baz:
token_created_after: 2019-10-02T15:00:00Z
Workflow example
Suppose the current org_repo_config in the managed_webhooks configuration is
qux:
token_created_after: 2017-10-02T15:00:00Z
foo/bar:
token_created_after: 2018-10-02T15:00:00Z
foo/baz:
token_created_after: 2019-10-02T15:00:00Z
There can be 3 scenarios to modify the configuration, as explained below:
Rotate an existing HMAC token
User updates the token_created_after for foo/baz to a later time, as shown below:
qux:
token_created_after: 2017-10-02T15:00:00Z
foo/bar:
token_created_after: 2018-10-02T15:00:00Z
foo/baz:
token_created_after: 2020-03-02T15:00:00Z
The hmac tool will generate a new HMAC token for the foo/baz repo,
add the new token to the secret, and update the webhook for the repo.
And after the update finishes, it will delete the old token.
Onboard a new repo
User adds a new repo foo/bax in the managed_webhooks configuration, as shown below:
qux:
token_created_after: 2017-10-02T15:00:00Z
foo/bar:
token_created_after: 2018-10-02T15:00:00Z
foo/baz:
token_created_after: 2019-10-02T15:00:00Z
foo/bax:
token_created_after: 2020-03-02T15:00:00Z
The hmac tool will generate an HMAC token for the foo/bax repo,
add the token to the secret, and add the webhook for the repo.
Remove an existing repo
User deletes the repo foo/baz from the managed_webhooks configuration, as shown below:
qux:
token_created_after: 2017-10-02T15:00:00Z
foo/bar:
token_created_after: 2018-10-02T15:00:00Z
The hmac tool will delete the HMAC token for the foo/baz repo from
the secret, and delete the corresponding webhook for this repo.
Note the 3 types of config changes can happen together, and hmac tool
is able to handle all the changes in one single run.
2.6 - jenkins-operator
jenkins-operator is a controller that enables Prow to use Jenkins
as a backend for running jobs.
Jenkins configuration
A Jenkins master needs to be provided via --jenkins-url in order for
the operator to make requests to. By default, --dry-run is set to true
so the operator will not make any mutating requests to Jenkins, GitHub,
and Kubernetes, but you most probably want to set it to false.
The Jenkins operator expects to read the Prow configuration by default
in /etc/config/config.yaml which can be configured with --config-path.
The following stanza is config that can be optionally set in the Prow config file:
jenkins_operators:
- max_concurrency: 150
max_goroutines: 20
job_url_template: 'https://storage-for-logs/{{if eq .Spec.Type "presubmit"}}pr-logs/pull{{else if eq .Spec.Type "batch"}}pr-logs/pull{{else}}logs{{end}}{{if ne .Spec.Refs.Repo "origin"}}/{{.Spec.Refs.Org}}_{{.Spec.Refs.Repo}}{{end}}{{if eq .Spec.Type "presubmit"}}/{{with index .Spec.Refs.Pulls 0}}{{.Number}}{{end}}{{else if eq .Spec.Type "batch"}}/batch{{end}}/{{.Spec.Job}}/{{.Status.BuildID}}/'
report_template: '[Full PR test history](https://pr-history/{{if ne .Spec.Refs.Repo "origin"}}{{.Spec.Refs.Org}}_{{.Spec.Refs.Repo}}/{{end}}{{with index .Spec.Refs.Pulls 0}}{{.Number}}{{end}}).'
max_concurrency is the maximum number of Jenkins builds that can
run in parallel, otherwise the operator is not going to start new builds.
Defaults to 0, which means no limit.max_goroutines is the maximum number of goroutines that the operator
will spin up to handle all Jenkins builds. Defaulted to 20.job_url_template is a Golang-templated URL that shows up in the Details
button next to the GitHub job status context. A ProwJob is provided as input
to the template.report_template is a Golang-templated message that shows up in GitHub in
case of a job failure. A ProwJob is provided as input to the template.
Security
Various flavors of authentication are supported:
- basic auth, using
--jenkins-user and --jenkins-token-file.
- OpenShift bearer token auth, using
--jenkins-bearer-token-file.
- certificate-based auth, using
--cert-file, --key-file, and
optionally --ca-cert-file.
Basic auth and bearer token are mutually exclusive options whereas
cert-based auth is complementary to both of them.
If CSRF protection is enabled in Jenkins, --csrf-protect=true
needs to be used on the operator’s side to allow Prow to work correctly.
Logs
Apart from a controller, the Jenkins operator also runs a http server
to serve Jenkins logs. You can configure the Prow frontend to show
Jenkins logs with the following Prow config:
deck:
external_agent_logs:
- agent: jenkins
url_template: 'http://jenkins-operator/job/{{.Spec.Job}}/{{.Status.BuildID}}/consoleText'
Deck uses url_template to contact jenkins-operator when a user
clicks the Build log button of a Jenkins job (agent: jenkins).
jenkins-operator forwards the request to Jenkins and serves back
the response.
NOTE: Deck will display the Build log button on the main page when the agent is not kubernetes
regardless the external agent log was configured on the server side. Deck has no way to know if the server
side configuration is consistent when rendering jobs on the main page.
Job configuration
Below follows the Prow configuration for a Jenkins job:
presubmits:
org/repo:
- name: pull-request-unit
agent: jenkins
always_run: true
context: ci/prow/unit
rerun_command: "/test unit"
trigger: "((?m)^/test( all| unit),?(\\s+|$))"
You can read more about the different types of Prow jobs elsewhere.
What is interesting for us here is the agent field which needs to
be set to jenkins in order for jobs to be dispatched to Jenkins and
name which is the name of the job inside Jenkins.
The following parameters must be added within each Jenkins job:
Sharding
Sharding of Jenkins jobs is supported via Kubernetes labels and label
selectors. This enables Prow to work with multiple Jenkins masters.
Three places need to be configured in order to use sharding:
--label-selector in the Jenkins operator.label_selector in jenkins_operators in the Prow config.labels in the job config.
For example, one would set the following options:
--label-selector=master=jenkins-master in a Jenkins operator.
This option forces the operator to list all ProwJobs with master=jenkins-master.
label_selector: master=jenkins-master in the Prow config.
jenkins_operators:
- label_selector: master=jenkins-master
max_concurrency: 150
max_goroutines: 20
jenkins_operators in the Prow config can be read by multiple running operators
and based on label_selector, each operator knows which config stanza does it
need to use. Thus, --label-selector and label_selector need to match exactly.
labels: jenkins-master in the job config.
presubmits:
org/repo:
- name: pull-request-unit
agent: jenkins
labels:
master: jenkins-master
always_run: true
context: ci/prow/unit
rerun_command: "/test unit"
trigger: "((?m)^/test( all| unit),?(\\s+|$))"
Labels in the job config are set in ProwJobs during their creation.
Kubernetes client
The Jenkins operator acts as a Kubernetes client since it manages ProwJobs
backed by Jenkins builds. It is expected to run as a pod inside a Kubernetes
cluster and so it uses the in-cluster client config.
GitHub integration
The operator needs to talk to GitHub for updating commit statuses and
adding comments about failed tests. Note that this functionality may
potentially move into its own service, then the Jenkins operator will
not need to contact the GitHub API. The required options are already
defaulted:
github-token-path set to /etc/github/oauth. This is the GitHub bot
oauth token that is used for updating job statuses and adding comments
in GitHub.github-endpoint set to https://api.github.com.
Prometheus support
The following Prometheus metrics are exposed by the operator:
jenkins_requests is the number of Jenkins requests made.
verb is the type of request (GET, POST)handler is the path of the request, usually containing a
job name (eg. job/test-pull-request-unit).code is the status code of the request (200, 404, etc.).
jenkins_request_retries is the number of Jenkins request
retries made.jenkins_request_latency is the time for a request to roundtrip
between the operator and Jenkins.resync_period_seconds is the time the operator takes to complete
one reconciliation loop.prowjobs is the number of Jenkins prowjobs in the system.
job_name is the name of the job.type is the type of the prowjob: presubmit, postsubmit, periodic, batchstate is the state of the prowjob: triggered, pending, success, failure, aborted, error
If a push gateway needs to be used it can be configured in the Prow config:
push_gateway:
endpoint: http://prometheus-push-gateway
interval: 1m
2.7 - status-reconciler
status-reconciler ensures that changes to blocking presubmits in Prow configuration while PRs are
in flight do not cause those PRs to get stuck.
When the set of blocking presubmits changes for a repository, one of three cases occurs:
- a new blocking presubmit exists and should be triggered for every trusted pull request in flight
- an existing blocking presubmit is removed and should have its' status retired
- an existing blocking presubmit is renamed and should have its' status migrated
The status-reconciler watches the job configuration for Prow and ensures that the above actions
are taken as necessary.
To exclude repos from being reconciled, passing flag --denylist, this can be done repeatedly.
This is useful when moving a repo from prow instance A to prow instance B, while unwinding jobs from
prow instance A, the jobs are not expected to be blindly lablled succeed by prow instance A.
Note that status-reconciler is edge driven (not level driven) so it can’t be used retrospectively.
To update statuses that were stale before deploying status-reconciler,
you can use the migratestatus tool.
2.8 - tot
This is a placeholder page. Some contents needs to be filled.
2.8.1 - fallbackcheck
Ensure your GCS bucket layout is what tot expects to use. Useful when you want to transition
from versioning your GCS buckets away from Jenkins build numbers to build numbers vended
by prow.
fallbackcheck checks the existence of latest-build.txt files as per the documented GCS layout.
It ignores jobs that have no GCS buckets.
Install
go get sigs.k8s.io/prow/pkg/cmd/tot/fallbackcheck
Run
fallbackcheck -bucket GCS_BUCKET -prow-url LIVE_DECK_DEPLOYMENT
For example:
fallbackcheck -bucket https://gcsweb-ci.svc.ci.openshift.org/gcs/origin-ci-test/ -prow-url https://deck-ci.svc.ci.openshift.org/
2.9 - Gangway (Prow API)
Gangway is an optional component which allows you to interact with Prow in a programmatic way (through an API).
Architecture
See the design doc.
Gangway uses gRPC to serve several endpoints. These can be seen in the
gangway.proto file, which describes the gRPC endpoints. The
proto describes the interface at a high level, and is converted into low-level
Golang types into gangway.pb.go and
gangway_grpc.pb.go. These low-level Golang types are
then used in the gangway.go file to implement the high-level
intent of the proto file.
As Gangway only understands gRPC natively, if you want to use a REST client
against it you must deploy Gangway. For example, on GKE you can use Cloud
Endpoints and deploy Gangway behind a reverse proxy called “ESPv2”. This ESPv2
container will forward HTTP requests made to it to the equivalent gRPC endpoint
in Gangway and back again.
Configuration setup
Server-side configuration
Gangway has its own security check to see whether the client is allowed to, for
example, trigger the job that it wants to trigger (we don’t want to let any
random client trigger any Prow Job that Prow knows about). In the central Prow
config under the gangway section, prospective Gangway users can list
themselves in there. For an example, see the section filled out for Gangway’s
own integration tests and search for
allowed_jobs_filters.
Client-side configuration
The table below lists the supported endpoints.
| Endpoint |
Description |
| CreateJobExecution |
Triggers a new Prow Job. |
| GetJobExecution |
Get the status of a Prow Job. |
| ListJobExecutions |
List all Prow Jobs that match the query. |
See gangway.proto and the Gangway Google
client.
Tutorial
See the example.
2.10 - Sub
Triggers Prow jobs from Pub/Sub.
Sub is a Prow component that can trigger new Prow jobs (PJs) using Pub/Sub
messages. The message does not need to have the full PJ defined; instead you
just need to have the job name and some other key pieces of information (more on
this below). The rest of the data needed to create a full-blown PJ is derived
from the main Prow configuration (or inrepoconfig).
Deployment Usage
Sub can listen to Pub/Sub subscriptions (known as “pull subscriptions”).
When deploy the sub component, you need to specify --config-path to your prow config, and optionally
--job-config-path to your prowjob config if you have split them up.
Notable options:
--dry-run: Dry run for testing. Uses API tokens but does not mutate.--grace-period: On shutdown, try to handle remaining events for the specified duration.--port: On shutdown, try to handle remaining events for the specified duration.--github-app-id and --github-app-private-key-path=/etc/github/cert: Used to authenticate to GitHub for cloning operations as a GitHub app. Mutually exclusive with --cookiefile.--cookiefile: Used to authenticate git when cloning from https://... URLs. See http.cookieFile in man git-config.--in-repo-config-cache-size: Used to cache Prow configurations fetched from inrepoconfig-enabled repos.
flowchart TD
classDef yellow fill:#ff0
classDef cyan fill:#0ff
classDef pink fill:#f99
subgraph Service Cluster
PCM[Prow Controller Manager]:::cyan
Prowjob:::yellow
subgraph Sub
staticconfig["Static Config
(/etc/job-config)"]
inrepoconfig["Inrepoconfig
(git clone <inrepoconfig>)"]
YesOrNo{"Is my-prow-job-name
in the config?"}
Yes
No
end
end
subgraph Build Cluster
Pod:::yellow
end
subgraph GCP Project
subgraph Pub/Sub
Topic
Subscription
end
end
subgraph Message
Payload["{"data":
{"name":"my-prow-job-name",
"attributes":{"prow.k8s.io/pubsub.EventType": "..."},
"data": ...,
..."]
end
Message --> Topic --> Subscription --> Sub --> |Pulls| Subscription
staticconfig --> YesOrNo
inrepoconfig -.-> YesOrNo
YesOrNo --> Yes --> |Create| Prowjob --> PCM --> |Create| Pod
YesOrNo --> No --> |Report failure| Topic
Sending a Pub/Sub Message
Pub/Sub has a generic PubsubMessage type that has the following JSON structure:
{
"data": string,
"attributes": {
string: string,
...
},
"messageId": string,
"publishTime": string,
"orderingKey": string
}
The Prow-specific information is encoded as JSON as the string value of the data key.
Pull Server
All pull subscriptions need to be defined in Prow Configuration:
pubsub_subscriptions:
"gcp-project-01":
- "subscription-01"
- "subscription-02"
- "subscription-03"
"gcp-project-02":
- "subscription-01"
- "subscription-02"
- "subscription-03"
Sub must be running with GOOGLE_APPLICATION_CREDENTIALS environment variable pointing to the service
account credentials JSON file. The service account used must have the right permission on the
subscriptions (Pub/Sub Subscriber, and Pub/Sub Editor).
More information at https://cloud.google.com/pubsub/docs/access-control.
Periodic Prow Jobs
When creating your Pub/Sub message, for the attributes field, add a key
prow.k8s.io/pubsub.EventType with value
prow.k8s.io/pubsub.PeriodicProwJobEvent. Then for the data field, use the
following JSON as the value:
{
"name":"my-periodic-job",
"envs":{
"GIT_BRANCH":"v.1.2",
"MY_ENV":"overwrite"
},
"labels":{
"myLabel":"myValue",
},
"annotations":{
# GCP project where Prow Job statuses are published by Prow. Must also
# provide "prow.k8s.io/pubsub.topic" to take effect.
#
# It's highly recommended to configure this even if prowjobs are monitored
# by other means, because this is also where errors are reported when the
# jobs are failed to be triggered.
"prow.k8s.io/pubsub.project":"myProject",
# Unique run ID.
"prow.k8s.io/pubsub.runID":"asdfasdfasdf",
# GCP pubsub topic where Prow Job statuses are published by Prow. Must be a
# different topic from where this payload is published to.
"prow.k8s.io/pubsub.topic":"myTopic"
}
}
Note: the # lines are comments for purposes of explanation in this doc; JSON
does not permit comments so make sure to remove them in your actual payload.
The above payload will ask Prow to find and trigger the periodic job named
my-periodic-job, and add/overwrite the annotations and environment variables
on top of the job’s default annotations. The prow.k8s.io/pubsub.* annotations
are used to publish job statuses.
Note: periodic jobs always clone source code from ref (a branch) instead of a
specific SHA. If you need to trigger a job based on a specific SHA you can use a
postsubmit job instead.
Postsubmit Prow Jobs
Triggering presubmit job is similar to periodic jobs. Two things to change:
- instead of an attributes with key
prow.k8s.io/pubsub.EventType and value
prow.k8s.io/pubsub.PeriodicProwJobEvent, replace the value with prow.k8s.io/pubsub.PostsubmitProwJobEvent
- requires setting
refs instructing postsubmit jobs how to clone source code:
{
# Common fields as above
"name":"my-postsubmit-job",
"envs":{...},
"labels":{...},
"annotations":{...},
"refs":{
"org": "org-a",
"repo": "repo-b",
"base_ref": "main",
"base_sha": "abc123"
}
}
This will start postsubmit job my-postsubmit-job, clones source code from base_ref
at base_sha.
(There are more fields can be supplied, see full documentation)
Presubmit Prow Jobs
Triggering presubmit jobs is similar to postsubmit jobs. Two things to change:
- instead of an
attributes with key prow.k8s.io/pubsub.EventType and value
prow.k8s.io/pubsub.PostsubmitProwJobEvent, replace the value with prow.k8s.io/pubsub.PresubmitProwJobEvent
- for the
refs field, additionally supply a pulls field, like this:
{
# Common fields as above
"name":"my-presubmit-job",
"envs":{...},
"labels":{...},
"annotations":{...},
"refs":{
"org": "org-a",
"repo": "repo-b",
"base_ref": "main",
"base_sha": "abc123",
"pulls": [
{
"sha": "def456"
}
]
}
}
This will start presubmit job my-presubmit-job, clones source code like pull requests
defined under pulls, which merges to base_ref at base_sha.
(There are more fields that can be supplied, see full
documentation.
For example, if you want the job to be reported on the PR, add number field
right next to sha)
Gerrit Presubmits and Postsubmits
Gerrit presubmit and postsubmit jobs require some additional labels and
annotations to be specified in the pubsub payload if you wish for them to report
results back to the Gerrit change. Specifically the following annotations must
be supplied (values are examples):
annotations:
prow.k8s.io/gerrit-id: my-repo~master~I79eee198f020c2ff23d49dbe4d2b2ef7cdc4091b
prow.k8s.io/gerrit-instance: https://my-project-review.googlesource.com
labels:
prow.k8s.io/gerrit-patchset: "4"
prow.k8s.io/gerrit-revision: 2b8cafaab9bd3a829a6bdaa819a18f908bc677ca
3 - CLI Tools
3.1 - checkconfig
checkconfig loads the Prow configuration given with --config-path,
--job-config-path and --plugin-config in order to validate it.
Use checkconfig as a pre-submit for any repository holding Prow
configuration to ensure that check-ins do not break anything.
3.2 - config-bootstrapper
config-bootstrapper is used to bootstrap a configuration that would be incrementally updated by the
config-updater Prow plugin.
When a set of configurations do not exist (for example, on a clean redeployment or in a disaster
recovery situation), the config-updater plugin is not useful as it can only upload incremental
updates. This tool is meant to be used in those situations to set up the config to the correct
base state and hand off ownership to the plugin for updates.
Provide the config-bootstrapper with the latest state of the Prow configuration (plugins.yaml, config.yaml, any job configuration files) to boot-strap with the latest configuration.
Sample usage:
./config-bootstrapper \
--dry-run=false \
--source-path=. \
--config-path=prowconfig/config.yaml \
--plugin-config=prowconfig/plugins.yaml \
--job-config-path=prowconfig/jobs
3.3 - generic-autobumper
This tool automates the version upgrading of images such as the prow.k8s.io Prow deployment.
Its workflow is:
- Given a local git repo containing the manifests of Prow component deployment,
e.g., /config/prow/cluster folder in this repo.
- Find out the most recent tags of given prefixes in
gcr.io registry
and modify the yaml files with them.
git-commit the change, push it to the remote repo, and create/update a PR,
e.g., test-infra/pull/14249, for the change.
The cluster admins can upgrade the version of images by approving the PR.
Define Prow jobs to utilize this tool:
Requirement
We need to fulfil those requirements to use this tool:
-
a “committable” local repo, i.e., git-commit command can be executed successfully, e.g., git-config is set up correctly.
This can be achieved by clone the repo by extra_refs, e.g.,
extra_refs:
- org: kubernetes
repo: test-infra
base_ref: master
-
a GitHub token which has permissions
to be used by this tool to push changes and create PRs against the remote repo.
-
a yaml config file that specifies the follwing information passed in with the flag -config=FILEPATH:
-
For info about what should go in the config look at the documentation for the Options here and look at the example below.
e.g.,
gitHubLogin: "k8s-ci-robot"
gitHubToken: "/etc/github-token/oauth"
gitName: "Kubernetes Prow Robot"
gitEmail: "k8s.ci.robot@gmail.com"
onCallAddress: "https://storage.googleapis.com/kubernetes-jenkins/oncall.json"
skipPullRequest: false
gitHubOrg: "kubernetes"
gitHubRepo: "test-infra"
remoteName: "test-infra"
upstreamURLBase: "https://raw.githubusercontent.com/kubernetes/test-infra/master"
includedConfigPaths:
- "."
excludedConfigPaths:
- "config/prow-staging"
extraFiles:
- "config/jobs/kubernetes/kops/build-grid.py"
- "config/jobs/kubernetes/kops/build-pipeline.py"
- "releng/generate_tests.py"
- "images/kubekins-e2e/Dockerfile"
targetVersion: "latest"
prefixes:
- name: "Prow"
prefix: "gcr.io/k8s-prow/"
refConfigFile: "config/prow/cluster/deck_deployment.yaml"
stagingRefConfigFile: "config/prow-staging/cluster/deck_deployment.yaml"
repo: "https://github.com/kubernetes/test-infra"
summarise: true
consistentImages: true
- name: "Boskos"
prefix: "gcr.io/k8s-staging-boskos/"
refConfigFile: "config/prow/cluster/build/boskos.yaml"
stagingRefConfigFile: "config/prow-staging/cluster/boskos.yaml"
repo: "https://github.com/kubernetes-sigs/boskos"
summarise: false
consistentImages: true
- name: "Prow-Test-Images"
prefix: "gcr.io/k8s-testimages/"
repo: "https://github.com/kubernetes/test-infra"
summarise: false
consistentImages: false
3.4 - invitations-accepter
The invitations-accepter tool approves all pending repository invitations.
Usage
example:
invitations-accepter --dry-run=false --github-token-path=/etc/github/oauth
using with GitHub Apps
invitations-accepter --dry-run=false --github-app-id=12345 --github-app-private-key-path=/etc/github/cert
3.5 - mkpj
This is a placeholder page. Some contents needs to be filled.
3.6 - mkpod
This is a placeholder page. Some contents needs to be filled.
3.7 - Peribolos
Peribolos allows the org settings, teams and memberships to be declared in a yaml file. GitHub is then updated to match the declared configuration.
See the kubernetes/org repo, in particular the merge and update.sh parts of that repo for this tool in action.
Peribolos was the subject of a KubeCon talk: How Kubernetes Uses GitOps to Manage GitHub Communities at Scale
Etymology
A peribolos is a wall that encloses a court in Greek/Roman architecture.
Org configuration
Extend the primary prow config.yaml document to include a top-level orgs key that looks like the following:
orgs:
this-org:
# org settings
company: foo
email: foo
name: foo
description: foo
has_organization_projects: true
has_repository_projects: true
default_repository_permission: read
members_can_create_repositories: false
# org member settings
members:
- anne
- bob
admins:
- carl
# team settings
teams:
node:
# team config
description: people working on node backend
privacy: closed
previously:
- backend # If a backend team exists, rename it to node
# team members
members:
- anne
maintainers:
- jane
repos: # Ensure the team has the following permissions levels on repos in the org
some-repo: admin
other-repo: read
another-team:
...
...
that-org:
...
This config will:
- Ensure the org settings match the following:
- Set the company, email, name and descriptions fields for the org to foo
- Allow projects to be created at the org and repo levels
- Give everyone read access to repos by default
- Disallow members from creating repositories
- Ensure the following memberships exist:
- anne and bob are members, carl is an admin
- Configure the node and another-team in the following manner:
- Set node’s description and privacy setting.
- Rename the backend team to node
- Add anne as a member and jane as a maintainer to node
- Similar things for another-team (details elided)
- Ensure that the team has admin rights to
some-repo, read access to other-repo and no other privileges
Note that any fields missing from the config will not be managed by peribolos. So if description is missing from the org setting, the current value will remain.
For more details please see GitHub documentation around edit org, update org membership, edit team, update team membership.
Initial seed
Peribolos can dump the current configuration to an org. For example you could dump the kubernetes org do the following:
$ go run ./prow/cmd/peribolos --dump kubernetes-sigs --github-token-path ~/github-token | tee ~/current.yaml
...
INFO: Build completed successfully, 1 total action
...
{"client":"github","component":"peribolos","level":"info","msg":"GetOrg(kubernetes-sigs)","time":"2018-09-28T13:17:42-07:00"}
{"client":"github","component":"peribolos","level":"info","msg":"ListOrgMembers(kubernetes-sigs, admin)","time":"2018-09-28T13:17:42-07:00"}
{"client":"github","component":"peribolos","level":"info","msg":"ListOrgMembers(kubernetes-sigs, member)","time":"2018-09-28T13:17:43-07:00"}
{"client":"github","component":"peribolos","level":"info","msg":"ListTeams(kubernetes-sigs)","time":"2018-09-28T13:17:45-07:00"}
{"client":"github","component":"peribolos","level":"info","msg":"ListTeamMembers(2671356, maintainer)","time":"2018-09-28T13:17:46-07:00"}
{"client":"github","component":"peribolos","level":"info","msg":"ListTeamMembers(2671356, member)","time":"2018-09-28T13:17:46-07:00"}
...
admins:
- calebamiles
- cblecker
- etc
billing_email: secret@example.com
company: ""
default_repository_permission: read
description: Org for Kubernetes SIG-related work
email: ""
has_organization_projects: true
has_repository_projects: true
location: ""
members:
- ameukam
- amwat
- ant31
- etc
teams:
application-admins:
description: admin access to application
maintainers:
- kow3ns
members:
- mattfarina
- prydonius
privacy: closed
architecture-tracking-admins:
description: admin permission for architecture-tracking
maintainers:
- jdumars
- bgrant0607
privacy: closed
# etc
Open ~/current.yaml and then delete any metadata you don’t want peribolos to manage (such as billing_email, or all the teams, etc).
Apply this config in dry-run mode to see what would happen (hopefully nothing since you just created it):
$ go run ./prow/cmd/peribolos --config-path ~/current.yaml --github-token-path ~/github-token # --confirm
{"client":"github","component":"peribolos","level":"info","msg":"GetOrg(kubernetes-sigs)","time":"2018-09-27T23:07:13Z"}
{"client":"github","component":"peribolos","level":"info","msg":"ListOrgInvitations(kubernetes-sigs)","time":"2018-09-27T23:07:13Z"}
{"client":"github","component":"peribolos","level":"info","msg":"ListOrgMembers(kubernetes-sigs, admin)","time":"2018-09-27T23:07:13Z"}
{"client":"github","component":"peribolos","level":"info","msg":"ListOrgMembers(kubernetes-sigs, member)","time":"2018-09-27T23:07:14Z"}
...
Settings
In order to mitigate the chance of applying erroneous configs, the peribolos binary includes a few safety checks:
--required-admins= - a list of people who must be configured as admins in order to accept the config (defaults to empty list)--min-admins=5 - the config must specify at least this many admins--require-self=true - require the bot applying the config to be an admin.
These flags are designed to ensure that any problems can be corrected by rerunning the tool with a fixed config and/or binary.
--maximum-removal-delta=0.25 - reject a config that deletes more than 25% of the current memberships.
This flag is designed to protect against typos in the configuration which might cause massive, unwanted deletions. Raising this value to 1.0 will allow deleting everyone, and reducing it to 0.0 will prevent any deletions.
--confirm=false - no github mutations will be made until this flag is true. It is safe to run the binary without this flag. It will print what it would do, without actually making any changes.
See go run ./prow/cmd/peribolos --help for the full and current list of settings that can be configured with flags.
3.8 - Phaino
Run prowjobs on your local workstation with phaino.
Plato believed that ideas and forms are the ultimate truth,
whereas we only see the imperfect physical appearances of those idea.
He linkens this in his Allegory of the Cave to someone living in a cave
who can only see the shadows projected on the wall
from objects passing in front of a fire.
Phaino is act of making those imperfect shadows appear.
Phaino shares a prefix with Pharos, meaning lighthouse and in particular the ancient one in Alexandria.
Usage
Usage:
# Use a job from deck
go run ./prow/cmd/phaino $URL # or /path/to/prowjob.yaml
# Use mkpj to create the job
go run ./prow/cmd/mkpj --config-path=/path/to/prow/config.yaml --job-config-path=/path/to/prow/job/configs --job=foo > /tmp/foo
go run ./prow/cmd/phaino /tmp/foo
Phaino is an interactive utility; it will prompt you for a local copy of any secrets or
volumes that the Prow Job may require.
Common options
--grace=5m controls how long to wait for interrupted jobs before terminating--print the command that runs each job without running it--privileged jobs are allowed to run instead of rejected--timeout=10m controls how long to allow jobs to run before interrupting them--code-mount-path=/go changes the path where code is mounted in the container--skip-volume-mounts=volume1,volume2 includes the unwanted volume mounts that are defined in the job spec--extra-volume-mounts=/go/src/sigs.k8s.io/prow=/Users/xyz/k8s-test-infra includes the extra volume mounts needed for the container. Key is the mount path and value is the local path--skip-envs=env1,env2 includes the unwanted env vars that are defined in the job spec--extra-envs=env1=val1,env2=val2 includes the extra env vars needed for the container--use-local-gcloud-credentials controls whether to use the same gcloud credentials as local or not--use-local-kubeconfig controls whether to use the same kubeconfig as local or not
Common options usage scenarios
Phaino is smart at prompting for where repo is located, volume mounts etc., if
it’s desired to save the prompts, use the following tricks instead:
-
If the repo needs to be cloned under GOPATH, use:
--code-mount-path==/whatever/go/src # Controls where source code is mounted in container
--extra-volume-mounts=/whatever/go/src/sigs.k8s.io/prow=/Users/xyz/k8s-test-infra
-
If job requires mounting kubeconfig, assume the mount is named kubeconfig,use:
--use-local-kubeconfig
--skip-volume-mounts=kubeconfig
-
If job requires mounting gcloud default credentials, assume the mount is named service-account,use:
--use-local-gcloud-credentials
--skip-volume-mounts=service-account
-
If job requires mounting something else like name:foo; mountPath: /bar,use:
--extra-volume-mounts=/bar=/Users/xyz/local/bar
--skip-volume-mounts=foo
-
If job requires env vars,use:
--extra-envs=env1=val1,env2=val2
See go run ./prow/cmd/phaino --help for full option list.
Usage examples
URL example
- Go to your deck deployment
- Pick a job and click the rerun icon on the left
- Copy the URL (something like
https://prow.k8s.io/rerun?prowjob=d08f1ca5-5d63-11e9-ab62-0a580a6c1281)
- Paste it as a phaino arg
go run ./prow/cmd/phaino https://prow.k8s.io/rerun?prowjob=d08f1ca5-5d63-11e9-ab62-0a580a6c1281- Alternatively
go run ./prow/cmd/phaino <(curl $URL)
Configuration example
- Use
mkpj to create the job and pipe this to phaino
-
For prow.k8s.io jobs use //config:mkpj
go run ./config:mkpj --job=pull-test-infra-bazel > /tmp/foo
go run ./prow/cmd/phaino /tmp/foo
-
Other deployments will need to clone that rule and/or pass in extra flags:
go run ./prow/cmd/mkpj --config-path=/my/config.yaml --job=my-job
go run ./prow/cmd/phaino /tmp/foo
3.9 - Phony
phony sends fake GitHub webhooks.
Running a GitHub event manager
phony is most commonly used for testing hook and its plugins, but can be used for testing any externally exposed service configured to receive GitHub events (external plugins).
To get an idea of phony’s behavior, start a local instance of hook with
this:
go run prow/cmd/hook/main.go \
--config-path=config/prow/config.yaml \
--plugin-config=config/prow/plugins.yaml \
--hmac-secret-file=path/to/hmac \
--github-token-path=path/to/github-token
# Note:
# --hmac-secret-file is required for running locally, use the same hmac token for phony below
Usage
Once you have a running server that manages github webhook events, generate an
hmac token (same process as in prow), and point a phony pull
request event at it with the following:
phony --help
Usage of ./phony:
-address string
Where to send the fake hook. (default "http://localhost:8888/hook")
-event string
Type of event to send, such as pull_request. (default "ping")
-hmac string
HMAC token to sign payload with. (default "abcde12345")
-payload string
File to send as payload. If unspecified, sends "{}".
If you are testing hook and successfully sent the webhook from phony, you should see a log from hook resembling the following:
{"author":"","component":"hook","event-GUID":"GUID","event-type":"pull_request","level":"info","msg":"Pull request .","org":"","pr":0,"repo":"","time":"2018-05-29T11:38:57-07:00","url":""}
A list of supported events can be found in the GitHub API Docs. Some example event payloads can be found in the examples directory.
3.10 - tackle
Prow’s tackle utility walks you through deploying a new instance of prow
in a couple of minutes, try it out!
Installing tackle
Tackle at this point in time needs to be built from source. The following
steps will walk you through the process:
- Clone the
test-infra repository:
git clone git@github.com:kubernetes/test-infra.git
- Build
tackle (This requires a working go installation on your system)
cd test-infra/prow/cmd/tackle && go build -o tackle
- Optionally move
tackle to your $PATH
sudo mv tackle /usr/sbin/tackle
Deploying prow
Note: Creating a cluster using the tackle utility assumes you
have the gcloud application in your $PATH and are logged in. If you are
doing this on another cloud skip to the Manual deployment below.
Installing Prow using tackle will help you through the following steps:
- Choosing a kubectl context (or creating a cluster on GCP / getting its credentials if necessary)
- Deploying prow into that cluster
- Configuring GitHub to send prow webhooks for your repos. This is where you’ll provide the absolute
/path/to/github/token
To install prow run the following and follow the on-screen instructions:
- Run
tackle:
- Once your cluster is created, you’ll get a prompt to apply a
starter.yaml. Before you do that open another terminal and apply the prow CRDs using:
kubectl apply --server-side=true -f https://raw.githubusercontent.com/kubernetes/test-infra/master/config/prow/cluster/prowjob-crd/prowjob_customresourcedefinition.yaml
-
After that specify the starter.yaml you want to use (please make sure to replace the values mentioned here). Once that is done some pods still won’t be in the Running state because we haven’t created the secret containing the credentials needed for our GCS bucket. To do that follow the steps in Configure a GCS bucket.
-
Once that is done, tackle should show you the URL where you can access the prow dashboard. To use it with your repositories head over to the settings of the GitHub app you created and there under webhook secret, supply the HMAC token you specified in the starter.yaml.
-
Once that is done, install the GitHub app on the repositories you want (this is only needed if you ran tackle with the --skip-github flag) and you should now be able to use Prow :)
See the Next Steps section after running this utility.
4 - Pod Utilities
Pod utilities are small, focused Go programs used by plank to decorate user-provided PodSpecs
in order to increase the ease of integration for new jobs into the entire CI infrastructure. The
utilities today wrap the execution of the test code to ensure that the tests run against correct
versions of the source code, that test commands run in the appropriate environment and that output
from the test (in the form of status, logs and artifacts) is correctly uploaded to the cloud.
These utilities are integrated into a test run by adding InitContainers and sidecar Containers
to the user-provided PodSpec, as well as by overwriting the Container entrypoint for the test
Container provided by the user. The following utilities exist today:
clonerefs: clones source code under testinitupload: records the beginning of a test in cloud storage
and reports the status of the clone operationsentrypoint: is injected into the test Container, wraps the
test code to capture logs and exit statussidecar: runs alongside the test Container, uploads status, logs
and test artifacts to cloud storage once the test is finished
Why use Pod Utilities?
Writing a ProwJob that uses the Pod Utilities is much easier than writing one
that doesn’t because the Pod Utilities will transparently handle many of the
tasks the job would otherwise need to do in order to prepare its environment
and output more than pass/fail. Historically, this was achieved by wrapping
every job with a bootstrap.py script that handled cloning
source code, preparing the test environment, and uploading job metadata, logs,
and artifacts. This was cumbersome to configure and required every job to be
wrapped with the script in the job image. The pod utilities achieve the same goals
with less configuration and much simpler job images that are easier to develop
and less coupled to Prow.
Writing a ProwJob that uses Pod Utilities
What the test container can expect
Example test container script:
pwd # my repo root
ls path/to/file/in/my/repo.txt # access repo file
ls ../other-repo # access repo file in another repo
echo success > ${ARTIFACTS}/results.txt # result info that will be uploaded to GCS.
# logs, and job metadata are automatically uploaded.
More specifically, a ProwJob using the Pod Utilities can expect the following:
- Source Code - Jobs can expect to begin execution with their working
directory set as the root of the checked out repo. The commit that is checked
out depends on the type of job:
presubmit jobs will have the relevant PR checked out and merged with the base branch.postsubmit jobs will have the upstream commit that triggered the job checked out.periodic jobs will have the working directory set to the root of the repo specified by the first ref in extra_refs (if specified).
See the extra_refs field if you need to clone more than one repo.
- Metadata and Logs - Jobs can expect metadata about the job to be uploaded
before the job starts, and additional metadata and logs to be uploaded when the
job completes.
- Artifact Directory - Jobs can expect an
$ARTIFACTS environment variable
to be specified. It indicates an existent directory where job artifacts can be
dumped for automatic upload to GCS upon job completion.
In order to use the pod utilities, you will need to configure plank with some settings first.
See plank’s README for reference.
ProwJobs may request Pod Utility decoration by setting decorate: true in their config.
Example ProwJob configuration:
- name: pull-job
always_run: true
decorate: true
spec:
containers:
- image: alpine
command:
- "echo"
args:
- "The artifacts dir is $(ARTIFACTS)"
In addition to normal ProwJob configuration, ProwJobs using the Pod Utilities
must specify the command field in the container specification instead of using
the Dockerfile’s ENTRYPOINT directive. Note that the command field is a string
array not just a string. It should point to the test binary location in the container.
Additional fields may be required for some use cases:
- Private repos need to do two things:
- Add an ssh secret that gives the bot access to the repo to the build cluster
and specify the secret name in the
ssh_key_secrets field of the job decoration config.
- Set the
clone_uri field of the job spec to git@github.com:{{.Org}}/{{.Repo}}.git.
- Repos requiring a non-standard clone path can use the
path_alias field
to clone the repo to different go import path than the default of /home/prow/go/src/github.com/{{.Org}}/{{.Repo}}/ (e.g. path_alias: sigs.k8s.io/prow -> /home/prow/go/src/sigs.k8s.io/prow).
- Jobs that require additional repos to be checked out can arrange for that with
the
exta_refs field. If the cloned path of this repo must be used as a default working dir the workdir: true must be specified.
- Jobs that do not want submodules to be cloned should set
skip_submodules to true
- Jobs that want to perform shallow cloning can use
clone_depth field. It can be set to desired clone depth. By default, clone_depth get set to 0 which results in full clone of repo.
- name: post-job
decorate: true
decoration_config:
ssh_key_secrets:
- ssh-secret
clone_uri: "git@github.com:<YOUR_ORG>/<YOUR_REPO>.git"
extra_refs:
- org: kubernetes
repo: other-repo
base_ref: master
workdir: false
skip_submodules: true
clone_depth: 0
spec:
containers:
- image: alpine
command:
- "echo"
args:
- "The artifacts dir is $(ARTIFACTS)"
Migrating from bootstrap.py to Pod Utilities
Jobs using the deprecated bootstrap.py should switch to the Pod Utilities at
their earliest convenience. @dims has created a handy migration guide.
Automatic Censoring of Secret Data
Many jobs exist that must touch third-party systems in order to be productive. Whether the job provisions
resources in a cloud IaaS like GCP, reports results to an aggregation service like coveralls.io, or simply
clones private repositories, jobs require sensitive credentials to achieve their goals. Even with the best
intentions, it is possible for end-user code running in a test Pod for a ProwJob to accidentally leak
the content of those credentials. If Prow is configured to push job logs and artifacts to a public cloud
storage bucket, that leak is immediately immortalized in plain text for the world to read. The sidecar
utility can infer what secrets a job has access to and censor those secrets from the output. The following
job turns on censoring:
- name: censored-job
decorate: true
decoration_config:
censor_secrets: true
Censoring Process
The automatic censoring process is written to be as useful as possible while having a bounded impact on the
execution cost in resources and time for the job. In order to censor every possible leak, all keys in all
Secrets that are mounted into the test Pod are treated as sensitive data. For each of these keys, the
value of the key as well as the base-64 encoded value are censored from the job’s log as well as any
artifacts the job produces. If any archives (e.g. .tar.gz) are found in the output artifacts for a job,
they are unarchived in order to censor their contents on the fly before being re-archived and pushed up to
cloud storage.
In order to bound the impact in runtime and resource cost for censoring on the job, both the concurrency
and buffer size of the censoring algorithm are tunable. The overall steady-state memory footprint of the
censoring algorithm is simply the buffer size times the maximum concurrency. The buffer must be as large
as twice the length of the largest secret to be censored, but may be tuned to very small values in order
to decrease the memory footprint. Keep mind that this will increase overall disk I/O and therefore increase
the runtime of censoring. Therefore, in order to decrease censoring runtime the buffer should be increased.
Configuring Censoring
A number of aspects of the censoring algorithm are tunable with configuration option at the per-job level
or for entire repositories or organizations. Under the decoration_config stanza, the following options
are available to tune censoring:
decoration_config:
censoring_options:
censoring_concurrency: 0 # the number of files to censor concurrently; each allocates a buffer
censoring_buffer_size: 0 # the size of the censoring buffer, in bytes
include_directories:
- path/**/to/*something.txt # globs relative to $ARTIFACTS that should be censored; everything censored if unset
exclude_directories:
- path/**/to/*other.txt # globs relative to $ARTIFACTS that should not be censored
4.1 - clonerefs
clonerefs clones code under test at the specified locations. Regardless of the success or failure
of clone operations, this utility will have an exit code of 0 and will record the clone operation
status to the specified log file. Clone records have the form:
[
{
"failed": false,
"refs": {
"org": "kubernetes",
"repo": "kubernetes",
"base_ref": "master",
"base_sha": "a36820b10cde020818b8dd437e285d0e2e7d5e98",
"pulls": [
{
"number": 123,
"author": "smarterclayton",
"sha": "2b58234a8aee0d55918b158a3b38c292d6a95ef7"
}
]
},
"commands": [
{
"command": "git init",
"output": "Reinitialized existing Git repository in /go/src/k8s.io/kubernetes/.git/",
"error": ""
}
]
}
]
Note: the utility will exit with a non-zero status if a fatal error is detected and no clone
operations can even begin to run.
This utility is intended to be used with initupload, which will
decode the JSON output by clonerefs and can format it for human consumption.
clonerefs can be configured by either passing in flags or by specifying a full set of options
as JSON in the $CLONEREFS_OPTIONS environment variable, which has the form:
{
"src_root": "/go",
"log": "/logs/clone-log.txt",
"git_user_name": "ci-robot",
"git_user_email": "ci-robot@k8s.io",
"refs": [
{
"org": "kubernetes",
"repo": "kubernetes",
"base_ref": "master",
"base_sha": "a36820b10cde020818b8dd437e285d0e2e7d5e98",
"pulls": [
{
"number": 123,
"author": "smarterclayton",
"sha": "2b58234a8aee0d55918b158a3b38c292d6a95ef7"
}
],
"skip_submodules": true,
"clone_depth": 0
}
]
}
4.2 - entrypoint
entrypoint wraps a process and records its output to stdout and stderr as well as its exit
code, recording both to disk. The utility will exit with a non-zero exit code if the wrapped
process fails or if the utility has a fatal error.
This utility is intended to be used with sidecar, which will
watch the files written by this utility and report on the status of the wrapped process.
entrypoint can be configured by either passing in flags or by specifying a full set of options
as JSON in the $ENTRYPOINT_OPTIONS environment variable, which has the form:
{
"args": [
"/bin/ls",
"-la"
],
"timeout": 7200000000000,
"grace_period": 15000000000,
"process_log": "/logs/process-log.txt",
"marker_file": "/logs/marker-file.txt"
}
Note: the "timeout" and "grace_period" fields hold the duration in nanoseconds.
4.3 - initupload
initupload reads clone records placed by clonerefs in order to determine job status. The status
and logs from the clone operations are uploaded to cloud storage at a path resolved from the job
configuration. This utility will exit with a non-zero exit code if the clone records indicate that
any clone operations failed, as well as if any fatal errors are encountered in this utility itself.
initupload can be configured by either passing in flags or by specifying a full set of options
as JSON in the $INITUPLOAD_OPTIONS environment variable, which has the same form as that for
gcsupload, plus the "log" field. See that documentation for
an explanation.
{
"log": "/logs/clone-log.txt",
"bucket": "kubernetes-jenkins",
"sub_dir": "",
"items": [
"/logs/artifacts/"
],
"path_strategy": "legacy",
"default_org": "kubernetes",
"default_repo": "kubernetes",
"gcs_credentials_file": "/secrets/gcs/service-account.json",
"dry_run": "false"
}
In addition to this configuration for the tool, the $JOB_SPEC environment variable should be
present to provide the contents of the Prow downward API for jobs. This data is used to resolve
the exact location in GCS to which artifacts and logs will be pushed.
4.4 - sidecar
sidecar watches disk for files containing a the std{out,err} output from a process as well as
its exit code; when the exit code has been written, this utility uploads a status object, the logs
from the process and any other specified artifacts to cloud storage. The utility will exit with the
exit code of the wrapped process or otherwise non-zero if the utility has a fatal error.
This utility is intended to be used with entrypoint, which will
write the files watched by this utility.
sidecar can be configured by either passing in flags or by specifying a full set of options
as JSON in the $SIDECAR_OPTIONS environment variable, which has the same form as that for
gcsupload, plus the "process_log" and "marker_file" fields. See
that documentation for an explanation.
{
"wrapper_options": {
"process_log": "/logs/process-log.txt",
"marker_file": "/logs/marker-file.txt"
},
"gcs_options": {
"bucket": "kubernetes-jenkins",
"sub_dir": "",
"items": [
"/logs/artifacts/"
],
"path_strategy": "legacy",
"default_org": "kubernetes",
"default_repo": "kubernetes",
"gcs_credentials_file": "/secrets/gcs/service-account.json",
"dry_run": "false"
}
}
In addition to this configuration for the tool, the $JOB_SPEC environment variable should be
present to provide the contents of the Prow downward API for jobs. This data is used to resolve
the exact location in GCS to which artifacts and logs will be pushed.
5 - Plugins
Plugins are sub-components of hook that consume GitHub webhooks related to their function and can be individually enabled per repo or org.
All plugin specific configuration is stored in plugins.yaml.
The Configuration golang struct holds all the config fields organized into substructures by plugin. See its GoDoc for up-to-date descriptions of every config option.
Most plugins lack README’s but instead generate PluginHelp structs on demand that include general explanations and help information in addition to details about the current configuration.
Please see https://prow.k8s.io/plugins for a list of all plugins deployed on the Kubernetes Prow instance, what they do, and what commands they offer.
For an alternate view, please see https://prow.k8s.io/command-help to see all of the commands offered by the deployed plugins.
How to enable a plugin on a repo
Add an entry to plugins.yaml. If you misspell the name then a
unit test will fail. If you have updateconfig plugin
deployed then the config will be automatically updated once the PR is merged,
else you will need to run make update-plugins. This does not require
redeploying the binaries, and will take effect within a minute.
External Plugins
External plugins offer an alternative to compiling a plugin into the hook binary. Any web endpoint that can properly handle GitHub webhooks can be configured as an external plugin that hook will forward webhooks to. External plugin endpoints are specified per org or org/repo in plugins.yaml under the external_plugins field. Specific event types may be optionally specified to filter which events are forwarded to the endpoint.
External plugins are well suited for:
- Slow operations that would impact the performance of other plugins if run as part of
hook.
- Components that need to be triggered or notified of events beside GitHub webhooks.
- Isolating a more or less privileged plugin or a plugin that executes PR code.
- Integrating existing GitHub services with Prow.
Examples of external plugins can be found in the prow/external-plugins directory. The following is an example external plugin configuration that would live in plugins.yaml.
external_plugins:
org-foo/repo-bar:
- name: refresh-remote
endpoint: https://my-refresh-plugin.com
events:
- issue_comment
- name: needs-rebase
# No endpoint specified implies "http://{{name}}".
events:
- pull_request
# Dispatching issue_comment events to the needs-rebase plugin is optional. If enabled, this may cost up to two token per comment on a PR. If `ghproxy`
# is in use, these two tokens are only needed if the PR or its mergeability changed.
- issue_comment
- name: cherrypick
# No events specified implies all event types.
How to test a plugin
See “Building, Testing, and Updating Prow”.
5.1 - approve
This is a placeholder page. Some contents needs to be filled.
5.1.1 - Reviewers and Approvers
Questions this Doc Seeks To Answer
- What are reviewers, approvers, and the OWNERS files?
- How does the reviewer selection mechanism work? approver selection mechanism work?
- How does an approver know which PR s/he has to approve?
Overview
Every GitHub directory which is a unit of independent code contains a file named “OWNERS”. The file lists reviewers and approvers for the directory. Approvers (or previously called assignees) are owners of the codes.
Approvers:
- have contributed substantially to the repo
- can provide an approval (
/approve) indicating whether a change to a directory or subdirectory should be accepted
- Approval is done on a per directory basis and subdirectories inherit their parents directory’s approvers
Reviewers:
- generally a larger set of current and past contributors
- They are responsible for a more thorough code review, discussing the implementation details and style
- Provide an
/lgtm when they are satisfied with the Pull Request. The /lgtm must be renewed whenever the Pull Request changes.
An example of the OWNERS file is listed below:
reviewers:
- jack
- ken
- lina
approvers:
- jack
- ken
- lina
Note that items in the OWNERS files can be GitHub usernames, or aliases defined in OWNERS_ALIASES files. An OWNERS_ALIASES file is another co-existed file that delivers a mechanism for defining groups. However, GitHub Team names are not supported. We do not use them because there is no audit log for changes to the GitHub Teams. This way we have an audit log.
Blunderbuss And Reviewers
lgtm Label
LGTM is abbreviation for “looks good to me”. The lgtm label is normally given when the code has been thoroughly reviewed. Getting it means the PR is one step away from getting merged. Reviewers of the PR give the label to a PR by typing /lgtm in a comment, or retract it by typing /lgtm cancel (at the beginning of a comment line). Authors of the PR cannot give the label, but they can cancel it. The bot retracts the label automatically if someone updates the PR with a new commit.
Any collaborator on the repo may use the /lgtm command, whether or not they are selected as a reviewer or approver by this plugin. (See the next section for reviewer and approver selection algorithm.)
Blunderbuss Selection Mechanism
Blunderbuss provides statistical means to select a subset of approvers found in OWNERS files for approving a PR. A PR consists of changes on one or more files, in which each file has different number of lines of codes changed. Blunderbuss determines the magnitude of code change within a PR using total number of lines of codes changed across various files. Number of reviewers selected for each PR is 2.
Algorithm for selecting reviewers is as follows:
-
determine potential reviewers of a file by going over all reviewers found in the OWNERS files for current and parent directories of the file (deduplication involved)
-
assign each changed file with a weightage based on number of lines of codes changed
-
assign each potential reviewer with a weightage by summing up weightages of all changed files in which s/he is a reviewer
-
randomly select 2 reviewers based on their weightage
Approval Handler and the Approved Label
approved Label
A PR cannot be merged into the repo without the approved label. In order for the approved label to be applied, every file modified by the PR must be approved (via /approve) by an approver from the OWNERs files. Note, this does not necessarily require multiple approvers. The process is best illustrated in the example below.
Approval Selection Mechanism
First, it is important to understand that ALL approvers in an OWNERS file can approve any file in that directory AND its subdirectories. Second, it is important to understand the somewhat-competing goals of the bot when selecting approvers:
-
Provide a subset of approvers that can approve all files in the PR
-
Provide a small subset of approvers and suggest the same reviewers as blunderbuss if possible (people can be both reviewers and approvers)
-
Do not always suggest the same set of people to approve and do not consistently suggest people from the root OWNERS file
The exact algorithm for selecting approvers is somewhat complex; it is an set cover approximation with consideration for existing assignees. To read it in depth, check out the approvers source code linked at the end of the README.
Example

Suppose files in directories E and G are changed in a PR created by PRAuthor. Any combination of approver(s) listed below can approve the PR in order to get it merged:
-
approvers found in OWNERS files for leaf (current) directories E and G
-
approvers found in OWNERS files for parent directories B and C
-
approvers found in OWNERS files for root directory A
Note someone can be both a reviewer found in OWNERS files for directory A and E. If s/he is selected as an approver and gives approval, it approves entire PR because s/he is also a reviewer for the root directory A.
Step 1:
K8s-bot creates a comment that suggests the selected approvers and shows a list of OWNERS file(s) where the approvers can be found.
[APPROVALNOTIFIER] This PR is **NOT APPROVED**
This pull-request has been approved by: *PRAuthor*
We suggest the following additional approvers: **approver1,** **approver2**
If they are not already assigned, you can assign the PR to them by writing `/assign @approver1 @approver2` in a comment when ready.
∇ Details
Needs approval from an approver in each of these OWNERS Files:
* /A/B/E/OWNERS
* /A/C/G/OWNERS
You can indicate your approval by writing `/approve` in a comment
You can cancel your approval by writing `/approve cancel` in a comment
A selected approver such as approver1 can be notified by typing /assign @approver1 in a comment.
Step 2:
approver1 is in the E OWNERS file. S/he writes /approve
K8s-bot updates comment:
[APPROVALNOTIFIER] This PR is **NOT APPROVED**
This pull-request has been approved by: *approver1, PRAuthor*
We suggest the following additional approver: **approver2**
If they are not already assigned, you can assign the PR to them by writing /assign @approver2 in a comment when ready.
∇ Details
Needs approval from an approver in each of these OWNERS Files:
* ~/A/B/E/OWNERS~ [approver1]
* /A/C/G/OWNERS
You can indicate your approval by writing `/approve` in a comment
You can cancel your approval by writing `/approve cancel` in a comment
Step 3:
approver3 (an approver for D) is NOT an approver for any of the affected directories. S/he writes /approve
K8s-bot updates comment:
[APPROVALNOTIFIER] This PR is **NOT APPROVED**
This pull-request has been approved by: *approver1, approver3, PRAuthor*
We suggest the following additional approvers: **approver2**
If they are not already assigned, you can assign the PR to them by writing /assign @approver1 @approver2 in a comment when ready.
∇ Details
Needs approval from an approver in each of these OWNERS Files:
* ~/A/B/E/OWNERS~ [approver1]
* /A/C/G/OWNERS
You can indicate your approval by writing `/approve` in a comment
You can cancel your approval by writing `/approve cancel` in a comment
Step 4:
approver1 is an approver of the PR. S/he writes /lgtm
K8s-bot updates comment:
[APPROVALNOTIFIER] This PR is **NOT APPROVED**
This pull-request has been approved by: *approver1, approver3, PRAuthor*
We suggest the following additional approver: **approver2**
If they are not already assigned, you can assign the PR to them by writing /assign @approver2 in a comment when ready.
∇ Details
Needs approval from an approver in each of these OWNERS Files:
* ~/A/B/E/OWNERS~ [approver1]
* /A/C/G/OWNERS
You can indicate your approval by writing `/approve` in a comment
You can cancel your approval by writing `/approve cancel` in a comment
The lgtm label is immediately added to the PR.
Step 5:
approver2 (who in the C OWNERS file, which is a parent to G) writes /approve
K8s-bot updates comment:
[APPROVALNOTIFIER] This PR is **APPROVED**
The following people have approved this PR: *approver1, approver2, approver3, PRAuthor*
∇ Details
Needs approval from an approver in each of these OWNERS Files:
* ~/A/B/E/OWNERS~ [approver1]
* ~/A/C/G/OWNERS~ [approver2]
You can indicate your approval by writing `/approve` in a comment
You can cancel your approval by writing `/approve cancel` in a comment
The PR is now unblocked from merging. If Tide is configured, the K8s-bot merges the PR, because it has both the lgtm and approved. It K8s-bot still needs to wait its turn in submit queue and pass tests.

Configuration options
See the Approve go struct for documentation of the options for this plugin.
See also the Lgtm go struct for documentation of the LGTM plugin’s options.
Final Notes
Obtaining approvals from selected approvers is the last step towards merging a PR. The approvers approve a PR by typing /approve in a comment, or retract it by typing /approve cancel.
Algorithm for getting the status is as follow:
-
run through all comments to obtain latest intention of approvers
-
put all approvers into an approver set
-
determine whether a file has at least one approver in the approver set
-
add the status to the PR if all files have been approved
If an approval is cancelled, the bot will delete the status added to the PR and remove the approver from the approver set. If someone who is not an approver in the OWNERS file types /approve in a comment, the PR will not be approved. If someone who is an approver in the OWNERS file and s/he does not get selected, s/he can still type /approve or /lgtm in a comment, pushing the PR forward.
Code Implementation Links
Blunderbuss:
prow/plugins/blunderbuss/blunderbuss.go
LGTM:
prow/plugins/lgtm/lgtm.go
Approve:
prow/plugins/approve/approve.go
prow/plugins/approve/approvers/owners.go
5.2 - branchcleaner
The branchcleaner plugin automatically deletes source branches for merged PRs between two branches
on the same repository. This is helpful to keep repos that don’t allow forking clean.
Usage
Enable the branchcleaner in the desired repos via the plugins.yaml:
plugins:
org/repo:
- branchcleaner
5.4 - updateconfig
updateconfig allows prow to update configmaps when files in a repo change.
updateconfig also supports glob match, or multi-key updates.
Usage
Update your plugins.yaml file to something along the following lines:
plugins:
my-github/repo:
plugins:
- config-updater
config_updater:
maps:
# Update the thing-config configmap whenever thing changes
path/to/some/other/thing:
name: thing-config
# If cluster and namespace configuration are unset, it will be put into the default cluster in the prowjob namespace
path/to/some/other/thing2:
name: thing2-config
# Specify the clusters and namespaces that the configmap targets
# which requires that the --kubeconfig arg is enabled for Hook
# https://docs.prow.k8s.io/docs/getting-started-deploy/#run-test-pods-in-different-clusters
# if not set or empty, it uses the cluster where prow components are running
# and the specified namespace(s)
clusters:
others:
- namespace1
# Update the config configmap whenever config.yaml changes
config/prow/config.yaml:
name: config
# Update the plugin configmap whenever plugins.yaml changes
config/prow/plugins.yaml:
name: plugin
# Update the `this` or/and `that` key in the `data` configmap whenever `data.yaml` or/and `other-data.yaml` changes
some/data.yaml:
name: data
key: this
some/other-data.yaml:
name: data
key: that
# Update the fejtaverse configmap whenever any `.yaml` file under `fejtaverse` changes
fejtaverse/**/*.yaml:
name: fejtaverse
6 - External Plugins
This is a placeholder page. Some contents needs to be filled.
6.1 - cherrypicker
Cherrypicker is an external prow plugin that can also run as a standalone bot.
It automates cherry-picking merged PRs into different branches. Cherrypicks are
triggered from either comments or labels in GitHub PRs that need to be cherrypicked.
For comments:
/cherrypick release-1.10
The above comment will result in opening a new PR against the release-1.10 branch
once the PR where the comment was made gets merged or is already merged.
To use label, you need to apply labels that contain the name of the branch in the form:
cherrypick/XXX
where XXX is the name of the branch.
The bot uses its own fork to push patches that need to be cherry-picked and opens
PRs out of those patches. The fork is created automatically by the bot so there is
no need to set it up manually.
Required scopes for the oauth token that need to be used are read:org and repo.
7 - Deprecated Components
7.1 - cm2kc (clustermap to kubeconfig)
Description
cm2kc is a CLI tool used to convert a clustermap file to a kubeconfig file.
Usage
go run ./prow/cmd/cm2kc <options>
The following is a list of supported options for cm2kc:
-i, --input string Input clustermap file. (default "/dev/stdin")
-o, --output string Output kubeconfig file. (default "/dev/stdout")
Examples
Add a kubeconfig file in a secret: kubeconfig from a clustermap file in another secret: build-cluster for context: my-context
The following command will:
- Get a clustermap formatted secret:
build-cluster in key: cluster for context: my-context.
- Base64 decode the secret.
- Convert the clustermap data to a kubeconfig format.
- Create a kubeconfig formatted secret:
kubeconfig in key: config for context: my-context from the converted data.
kubectl --context=my-context get secrets build-cluster -o jsonpath='{.data.cluster}' |
base64 -d |
go run ./prow/cmd/cm2kc |
kubectl --context=my-context create secret generic kubeconfig --from-file=config=/dev/stdin
Lastly, to begin using this in Prow, update the volume mount and replace --build-cluster with --kubeconfig in the deployment of each relevant Prow component (e.g. crier, deck, plank, and sinker).
Create a kubeconfig file at path /path/to/kubeconfig.yaml from a clustermap file at path /path/to/clustermap.yaml
Ensure the clustermap file exists at the specified --input path:
# /path/to/clustermap.yaml
default:
clientCertificate: fake-default-client-cert
clientKey: fake-default-client-key
clusterCaCertificate: fake-default-ca-cert
endpoint: https://1.2.3.4
build:
clientCertificate: fake-build-client-cert
clientKey: fake-build-client-key
clusterCaCertificate: fake-build-ca-cert
endpoint: https://5.6.7.8
Execute cm2kc specifying an --input path to the clustermap file and an --output path to the desired location of the generated kubeconfig file:
go run ./prow/cmd/cm2kc --input=/path/to/clustermap.yaml --output=/path/to/kubeconfig.yaml
The following kubeconfig file will be created at the specified --output path:
# /path/to/kubeconfig.yaml
apiVersion: v1
clusters:
- name: default
cluster:
certificate-authority-data: fake-default-ca-cert
server: https://1.2.3.4
- name: build
cluster:
certificate-authority-data: fake-build-ca-cert
server: https://5.6.7.8
contexts:
- name: default
context:
cluster: default
user: default
- name: build
context:
cluster: build
user: build
current-context: default
kind: Config
preferences: {}
users:
- name: default
user:
client-certificate-data: fake-default-ca-cert
client-key-data: fake-default-ca-cert
- name: build
user:
client-certificate-data: fake-build-ca-cert
client-key-data: fake-build-ca-cert
7.2 - Plank
Plank is the controller that manages the job execution and lifecycle for jobs running in k8s.
Usage
go run ./prow/cmd/prow-controller-manager --help
Configuration
GCS and S3 are supported as the job log storage.
# config.yaml
plank:
# used to link to job results for decorated jobs (with pod utilities)
job_url_prefix_config:
'*': https://<domain>/view
# used to link to job results for non decorated jobs (without pod utilities)
job_url_template: 'https://<domain>/view/<bucket-name>/pr-logs/pull/{{.Spec.Refs.Repo}}/{{with index .Spec.Refs.Pulls 0}}{{.Number}}{{end}}/{{.Spec.Job}}/{{.Status.BuildID}}'
report_template: '[Full PR test history](https://<domain>/pr-history?org={{.Spec.Refs.Org}}&repo={{.Spec.Refs.Repo}}&pr={{with index .Spec.Refs.Pulls 0}}{{.Number}}{{end}})'
default_decoration_config_entries:
# All entries that match a job are used, later entries override previous values.
# Omission of 'repo' and 'cluster' fields makes this entry match all jobs.
- config:
timeout: 4h
grace_period: 15s
utility_images: # pull specs for container images used to construct job pods
clonerefs: gcr.io/k8s-prow/clonerefs:v20190221-d14461a
initupload: gcr.io/k8s-prow/initupload:v20190221-d14461a
entrypoint: gcr.io/k8s-prow/entrypoint:v20190221-d14461a
sidecar: gcr.io/k8s-prow/sidecar:v20190221-d14461a
gcs_configuration: # configuration for uploading job results to GCS
bucket: <bucket-name> or s3://<bucket-name>
path_strategy: explicit # or `legacy`, `single`
default_org: <github-org> # should not need this if `strategy` is set to explicit
default_repo: <github-repo> # should not need this if `strategy` is set to explicit
gcs_credentials_secret: <secret-name> # the name of the secret that stores cloud provider credentials
ssh_key_secrets:
- ssh-secret # name of the secret that stores the bot's ssh keys for GitHub, doesn't matter what the key of the map is and it will just uses the values
- repo: "^org/" # some regexp to match against <org/repo>
config:
timeout:2h
- cluster: "-trusted$" #some regexp to match against the cluster name
config:
# example override to use k8s SA with GCP workload identity rather than
# a GCP service account key file.
gcs_credentials_secret: ""
8 - Undocumented Components
8.1 - admission
This is a placeholder page. Some contents needs to be filled.
8.2 - grandmatriarch
This is a placeholder page. Some contents needs to be filled.
8.3 - pipeline
This is a placeholder page. Some contents needs to be filled.